
目录

实验环境
IDE:pycharm
python版本:anacoda->python3.7
实验1.1-requests库
原理

安装requests库
1 | pip install requests |
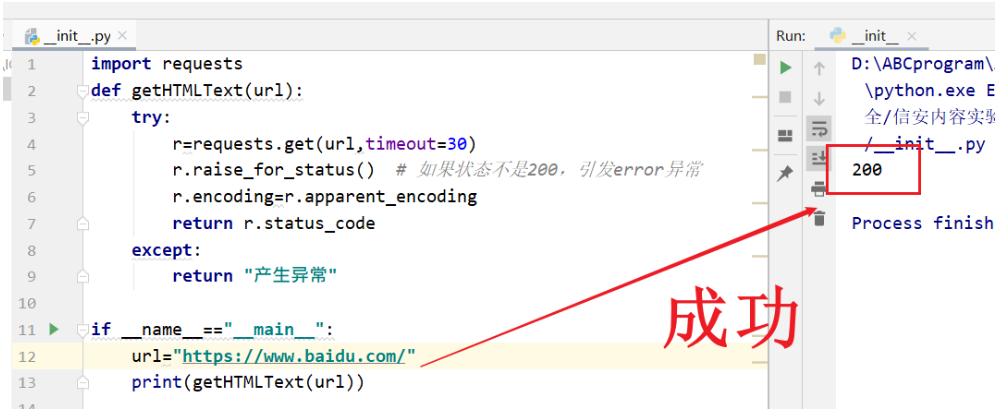
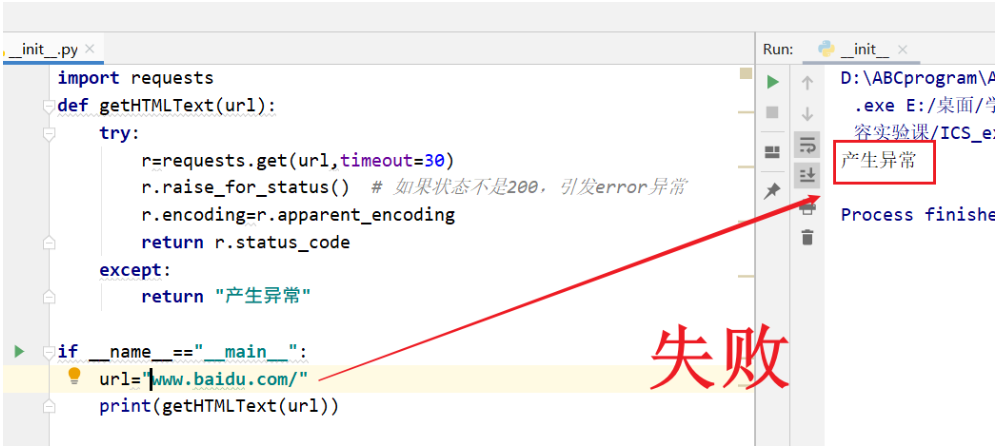
1.获取状态码
配置Python环境,使用通用代码框架爬取网站,并获取状态码。 爬取网址请自行选择。
1 | import requests |
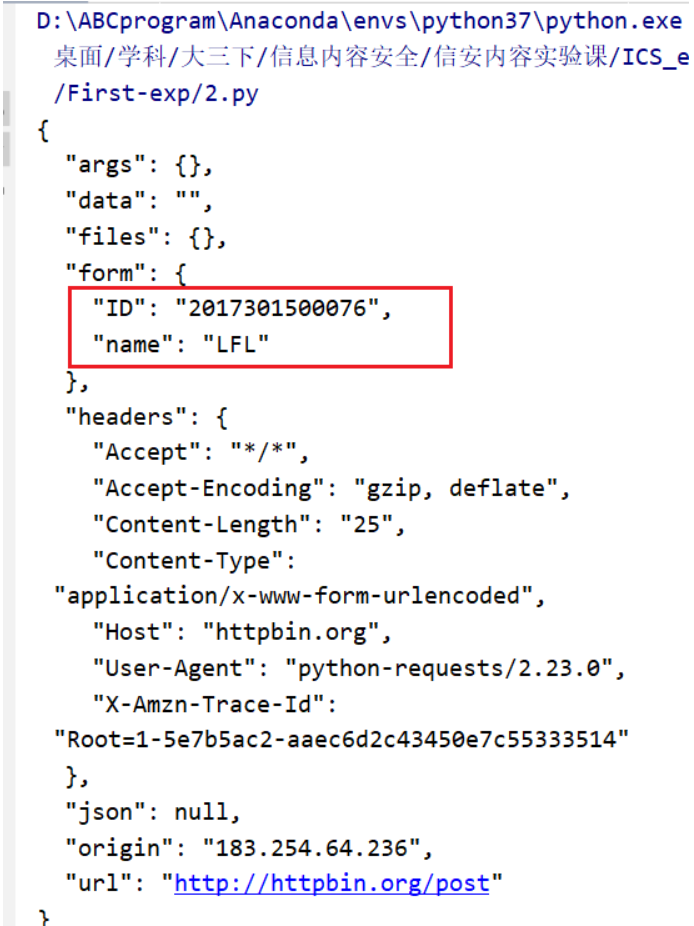
2.使用post()方法
使用requests库中的post()方法,向http://httpbin.org/post 增加字段,其中your_name和ID,请使用自己的姓名及学号。
1 | import requests |
3.实例1/2/3/4
完成实例1/2/3/4,其中实例1中的浏览器版本、实例2中搜索关键、实例3中下载图片、实例4 中的IP地址请自行选择。
1-亚马逊网站商品页面爬取
直接访问亚马逊会返回503访问异常错误
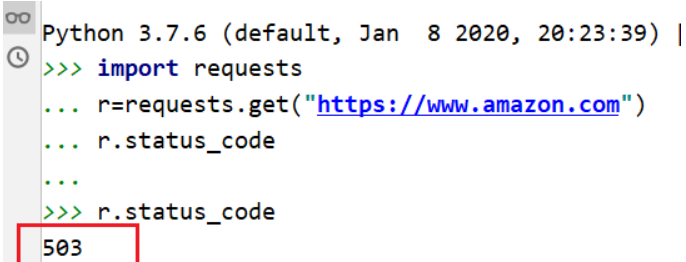
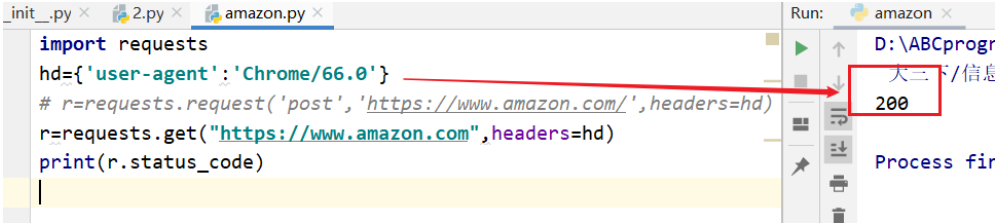
所以在头部加上浏览器版本
1 | import requests |
返回码200正确
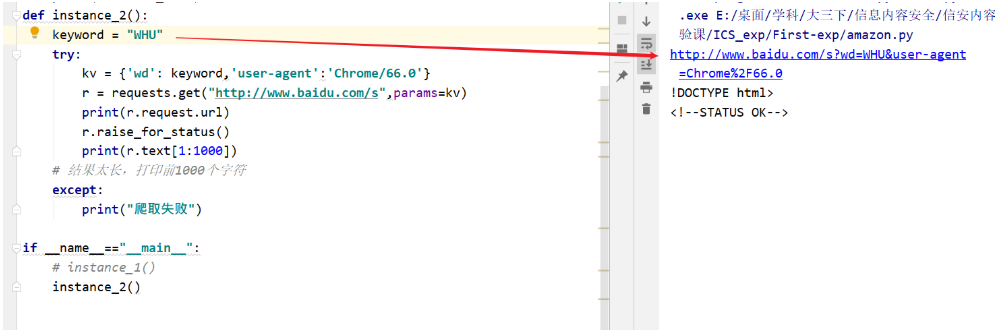
2-搜索引擎搜索关键词提交
1 | import requests |
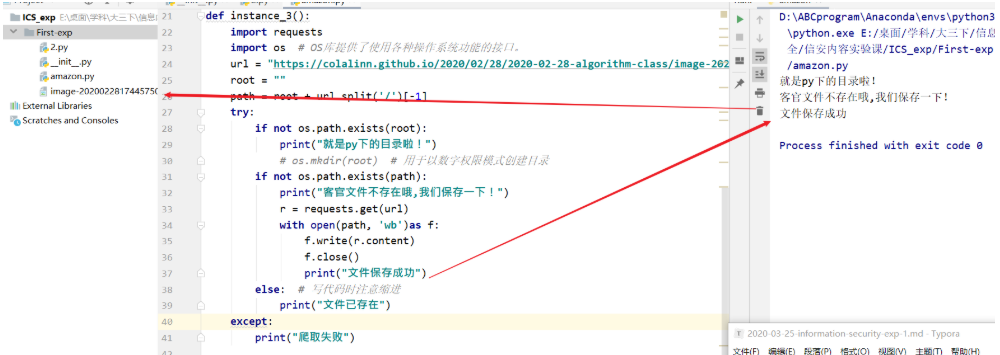
3-网络图片的爬取和存储
1 | def instance_3(): |
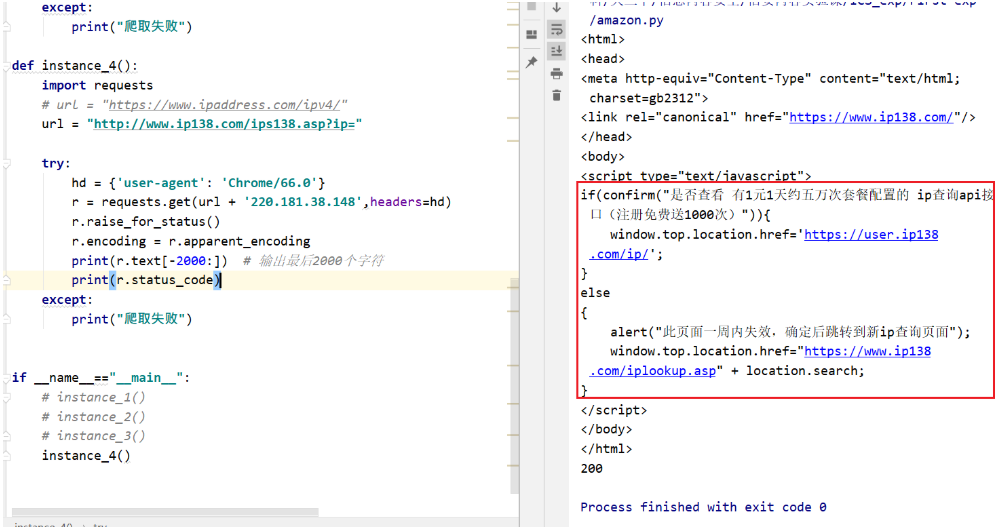
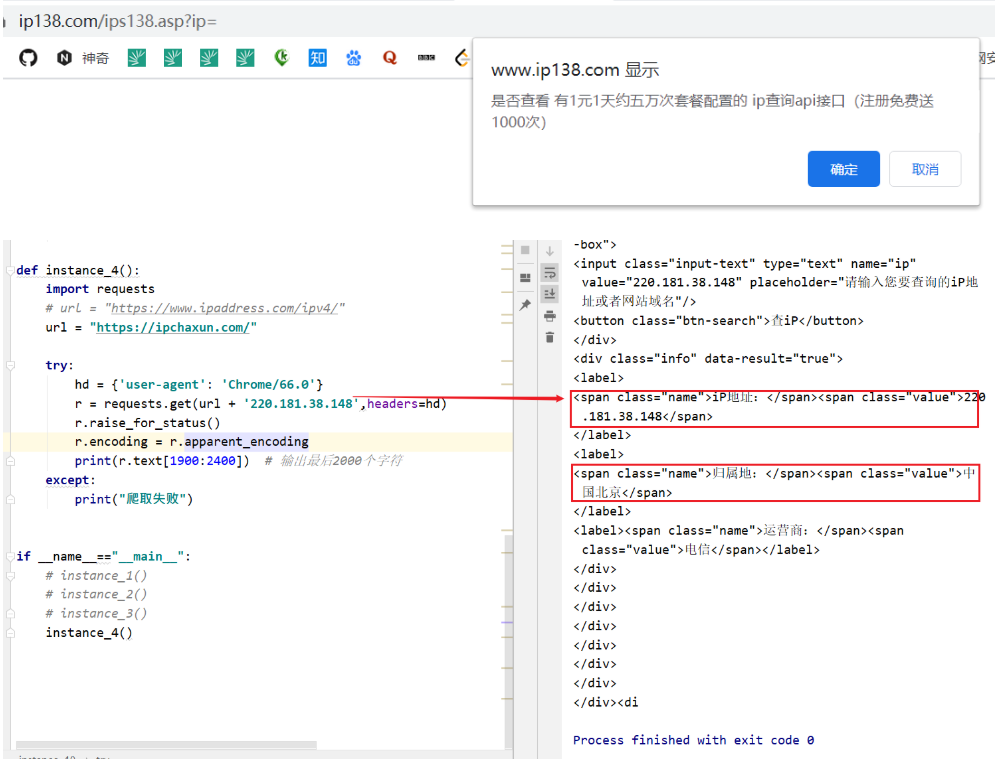
4-ip地址的查询
原ppt链接的网站会有一个弹窗,这里暂不改动
1 | def instance_4(): |
实验1.2-BeautifulSoup库
介绍
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过转换器实现文档导航、查找、修改。
安装
1 | pip install beautifulsoup4 |
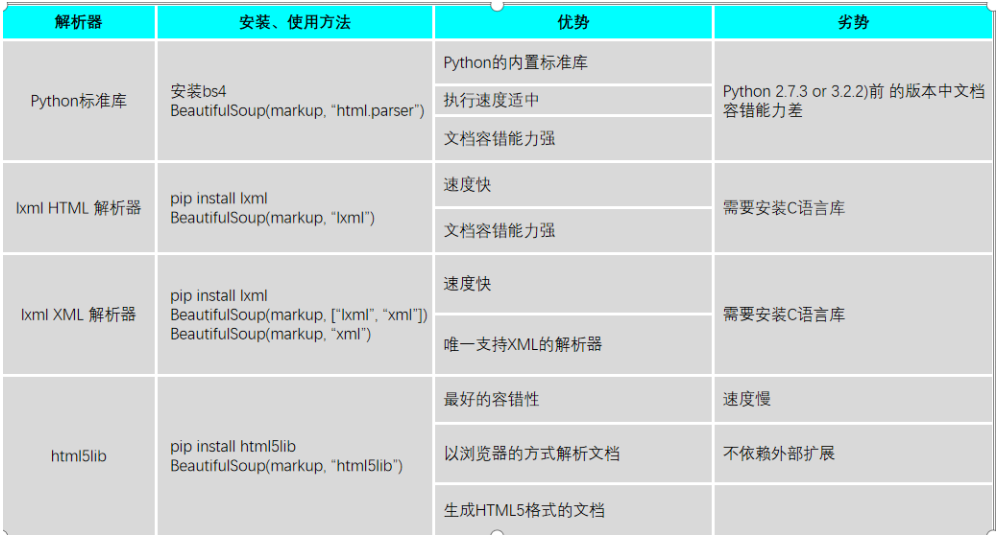
解析器
实验要求
- 参考实例2,爬取百度搜索风云榜 http://top.baidu.com/ 任一榜单,搜索结果按顺序逐行输出(含编号),榜单自选。
- 自行编码完成实例3,并回答思考题。
- 爬取当当图书排行榜(榜单自选),格式:爬取结果包含但不限于[排名 书名 作者], 注意输出格式对齐。
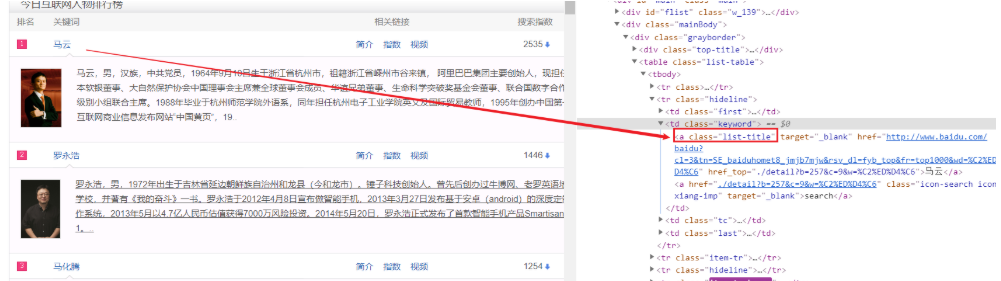
1-爬取百度搜索风云榜
使用审查可以看到百度搜索风云榜的标签都是a标签,属性是“list-title”
所以我们使用以下方式即可获取所有人物串
1 | soup.find_all('a', 'list-title') |
1 | def instance_2(): |
2-爬取中国大学排行榜+扩展
一开始我们的代码如下,
1 | def fillUnivList(ulist, html): |
结果是不对齐的,这是因为当中文字符宽度不够时,采用西文字符填充;中西文字符占用宽度不同
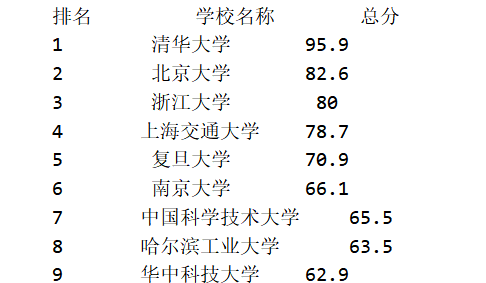
之后我们将printUnivList函数改成如下,排列对齐了
tplt为定义的输出格式模板变量:
- ^代表居中
- 4/12/10代表输出宽度(当输出数据超过该数字时,以实际输出为准)
- {3}代表打印输出时,我们使用chr(12288)中文空格对齐(全角Unicode空格)
1 | def printUnivList_A(ulist, num): |

扩展1-url改为2017
将实例2中url改为软科中国最好大学排名2017?
1 | url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html' |
会报错 排名找不到
我们将ulist打印出来,发现排名为none,说明没有获取到排名的值
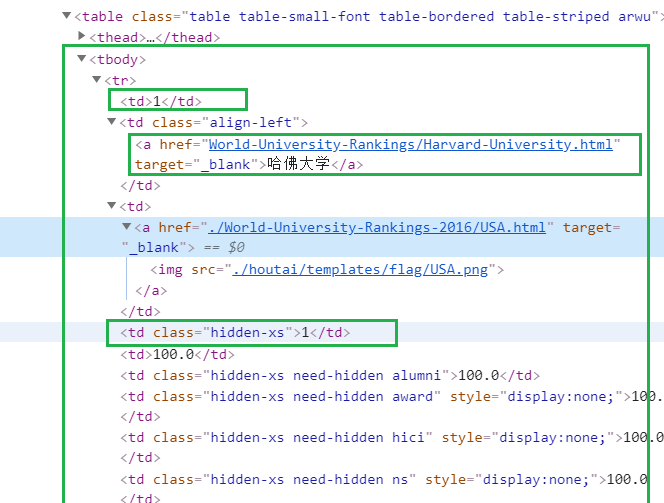
而我在chrome上审查,2017和2016的排名处格式是相同的

而在代码中使用soup.prettify()打印出来代码后发现排名处格式没有<td></td>的闭合,这里估计是用了javascript渲染时做了手脚使得td标签变了
1 | soup = BeautifulSoup(html, "html.parser") |
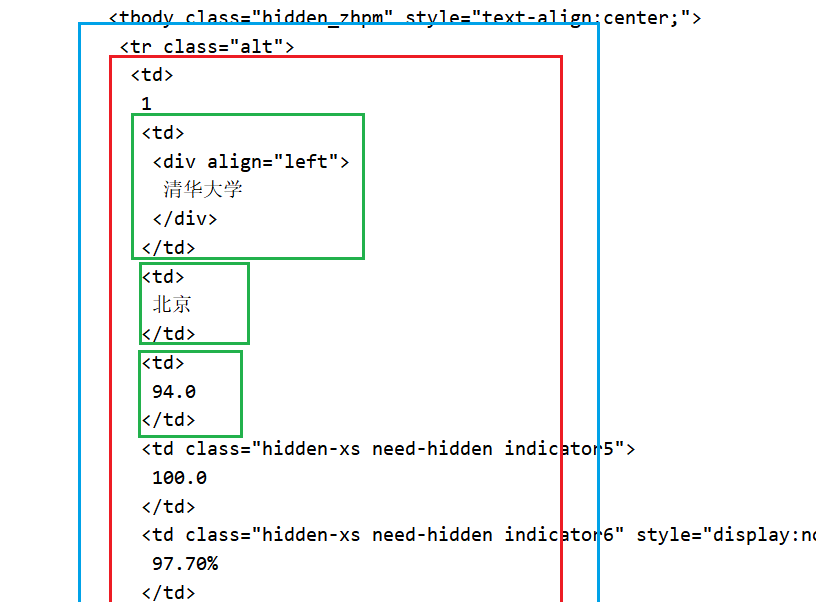
由图上可知,第一个td标签包含了所有内容,包括排名,所以无法通过tds[0]找到
解决方案:
使用contends
1 | tds[0].contents[0] #这个就是排名了 |
总代码
1 | def fillUnivList(ulist, html): |
最终结果
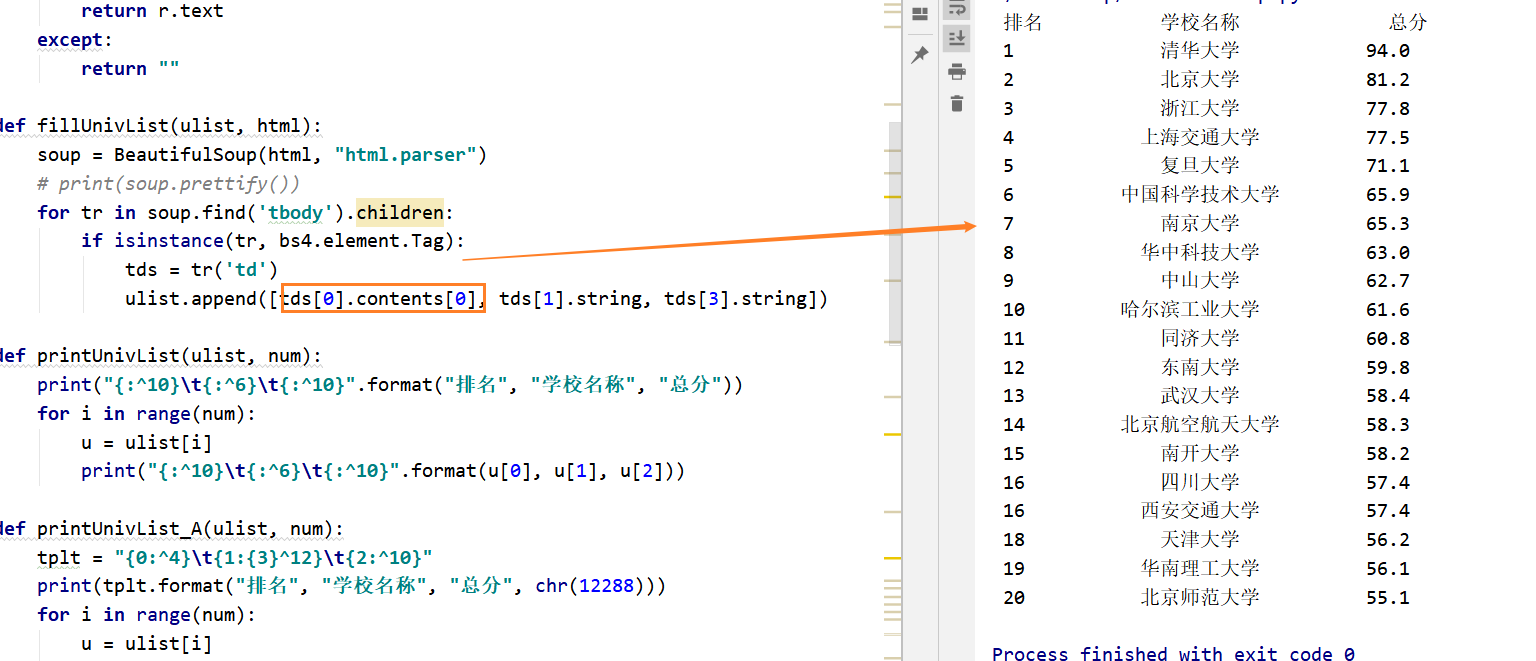
扩展2-url改为软科排名2016
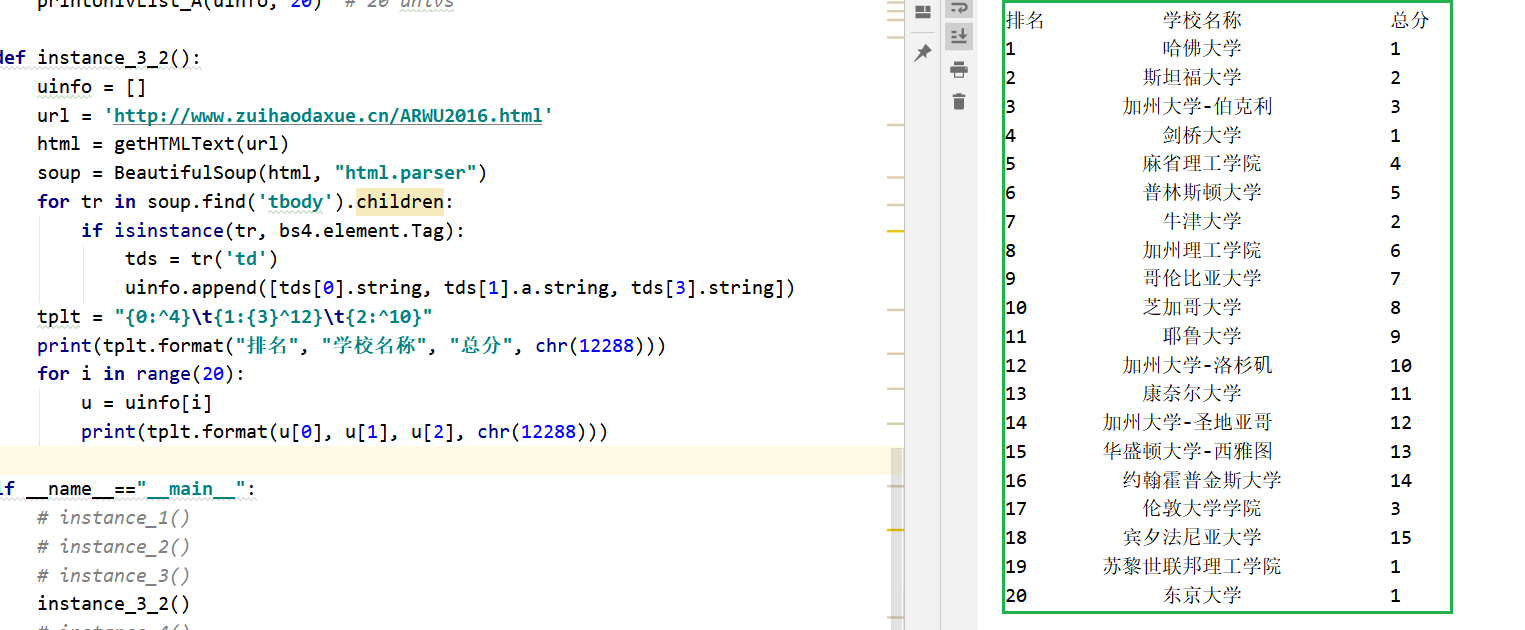
将实例2中url改为软科世界大学学术排名 2016:http://www.zuihaodaxue.cn/ARWU2016.html
该如何修改代码?
可以看到没有多大的变化,只是大学名、国家\地区有些不同
对之前的代码稍加修改可得结果
1 | def instance_3_2(): |
3.爬取当当图书排行榜(榜单自选)
格式:爬取结果包含但不限于[排名 书名 作者], 注意输出格式对齐。
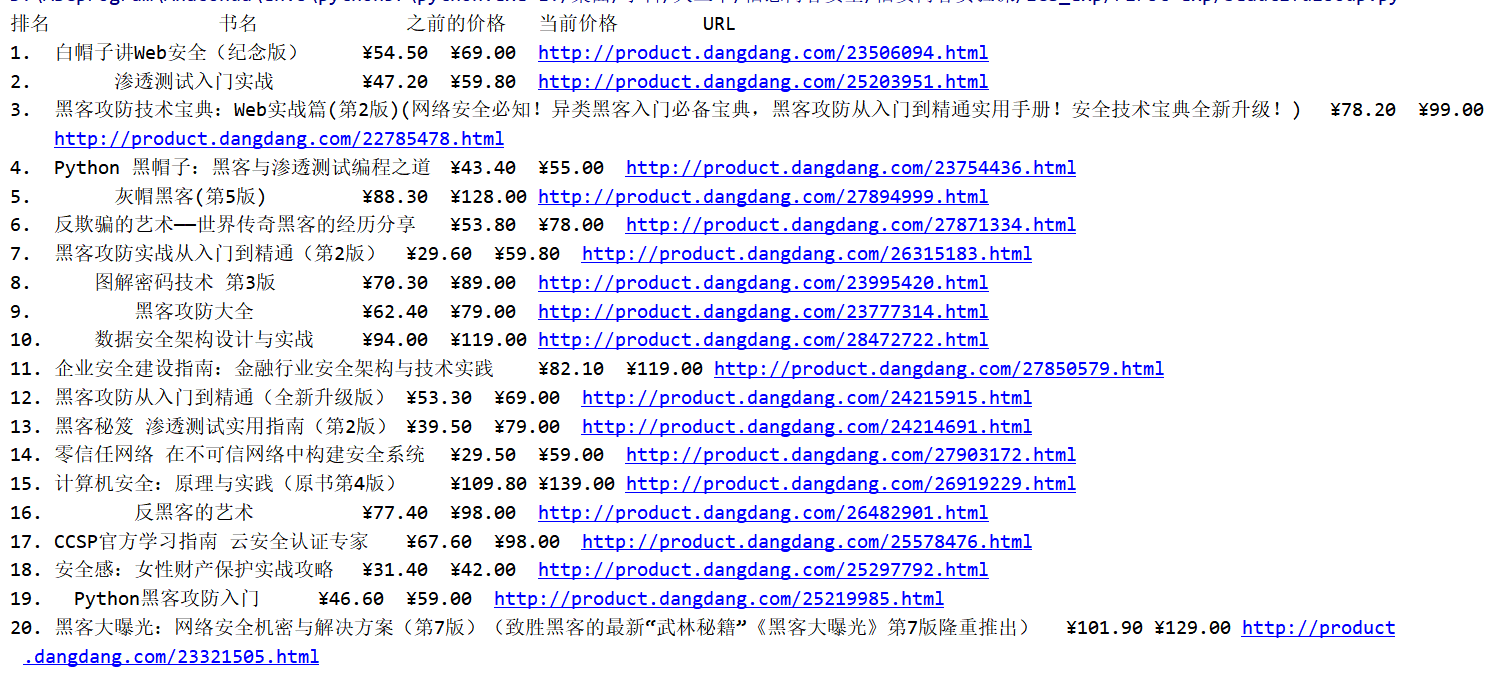
我这里爬取 信息安全类书籍的销量排行榜
http://bang.dangdang.com/books/bestsellers/01.54.19.00.00.00-24hours-0-0-1-1
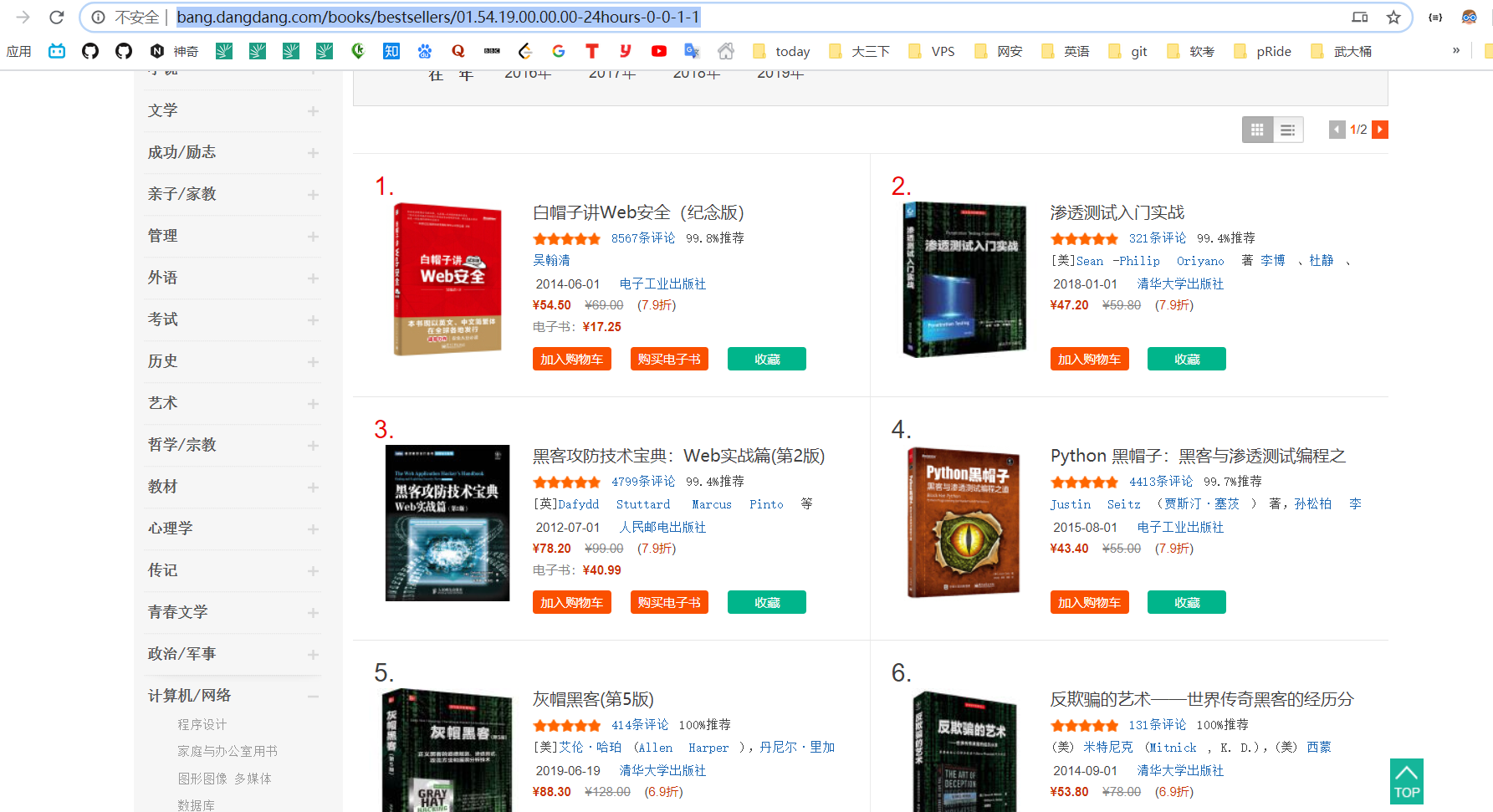
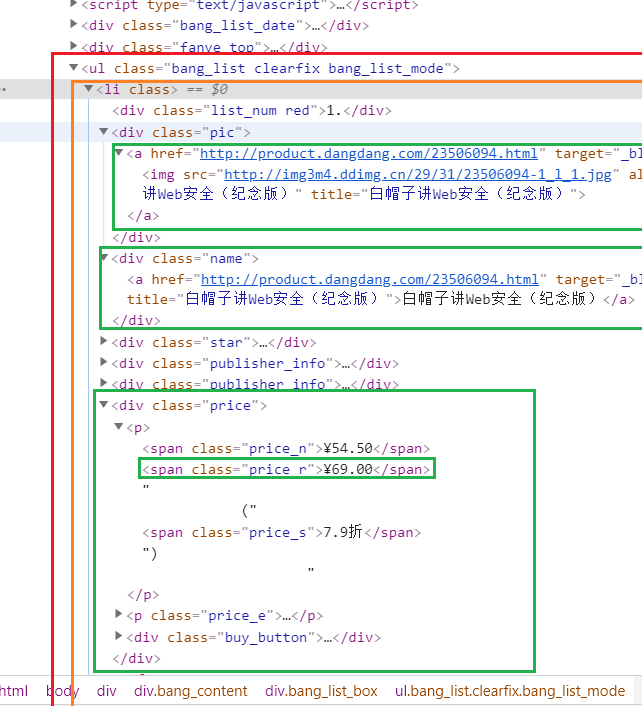
可以看到html结构如下
先从class为bang_list clearfix bang_list_mode中的ul遍历li
再从li中找出
- 排名
- 名字
- 现在的价格
- 之前的价格
- 链接
代码如下
1 | def instance_4(): |
结果如下!!!
实验2.1-正则式
介绍
正则表达式(Regular Expression,简写为regex或RE),使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
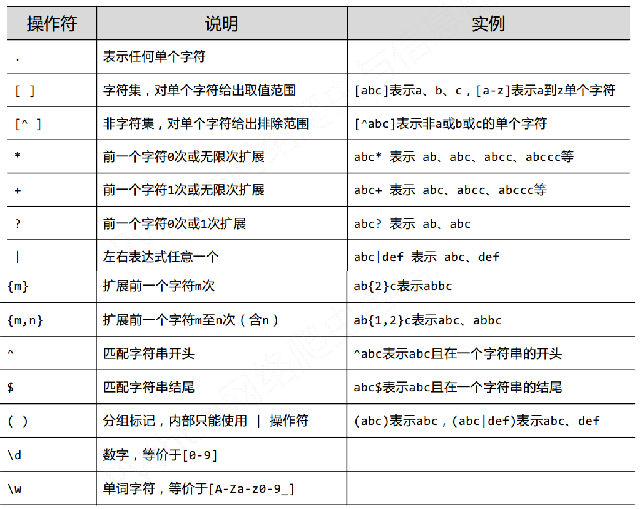

re库主要的方法如下

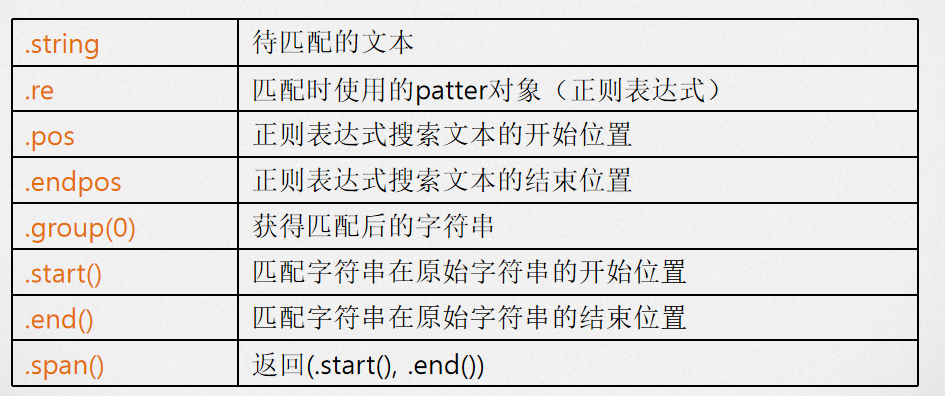
match对象包含了关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
只要长度输出可能不同的,都可以通过在操作符后增加?变成最小匹配

尝试爬取淘宝商品的数据
扫码登陆淘宝
搜索某个商品
发现商品分页的规律——如下,
第1页
https://s.taobao.com/search?q=airpodspro&s=0第2页
https://s.taobao.com/search?q=airpodspro&s=44第3页
https://s.taobao.com/search?q=airpodspro&s=88可以看出每页的s都是44累加的,这样我们想要遍历分页只需要遍历s即可
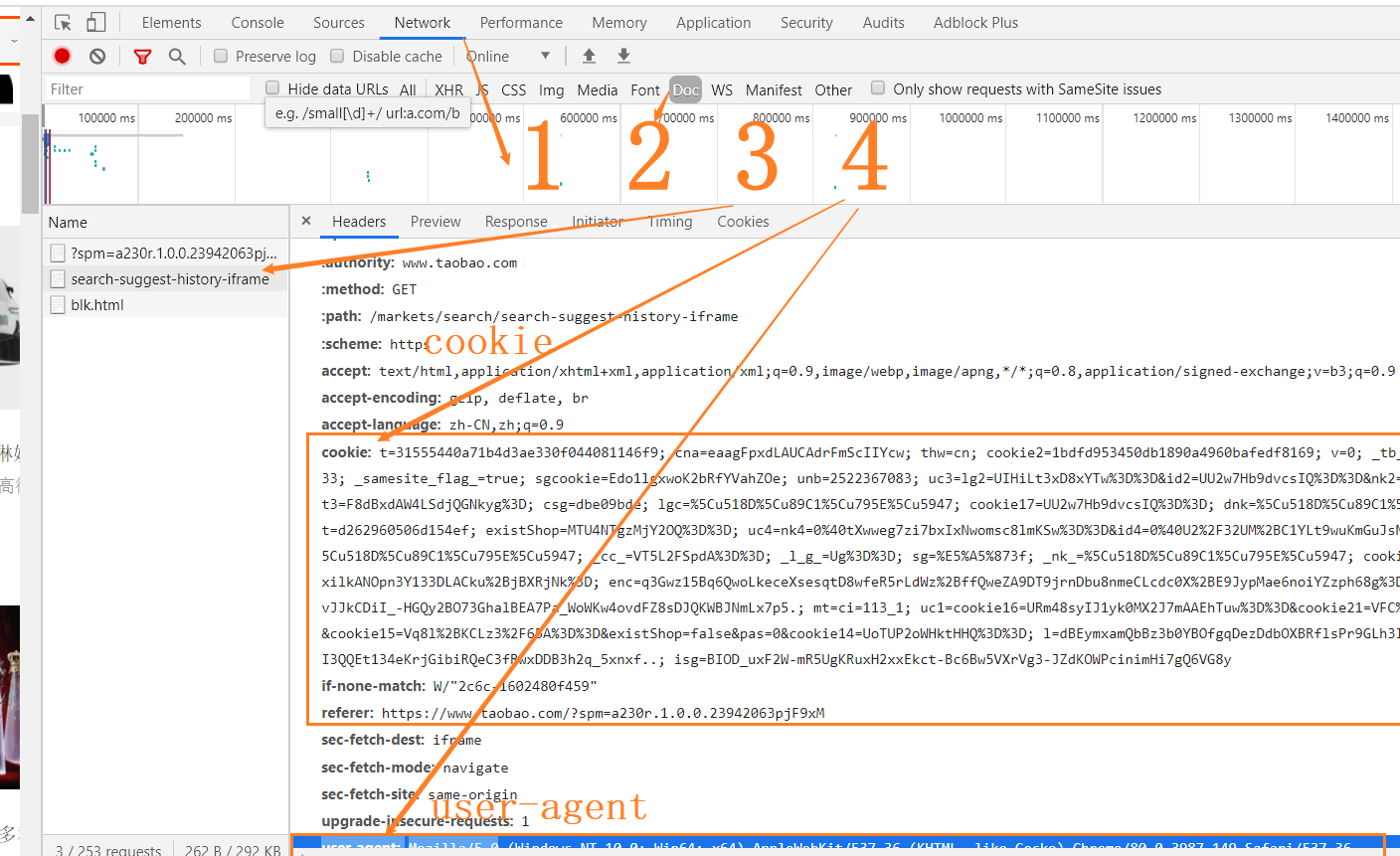
由于淘宝有反爬虫机制,我们要将手动登陆后的Cookies、agent复制到header中
- 扫码登陆淘宝
- 搜索商品,Chrome 下 F12打开审查
- 点击Network->Doc类型->search……->复制cookie、user-agent
- 将cookie、user-agent放到请求中,具体方式看代码
编写程序
1 | import requests |
功能说明:
main()主程序用于遍历商品页输出getHTMLText()用于获得htmlparsePage()用正则式搜索商品名称和价格printGoodsList()用于向命令行输出
这里写入txt——用python向txt文件中写数据时的追加和覆盖,我们使用a+
1 | with open("test.txt","w") as f: |
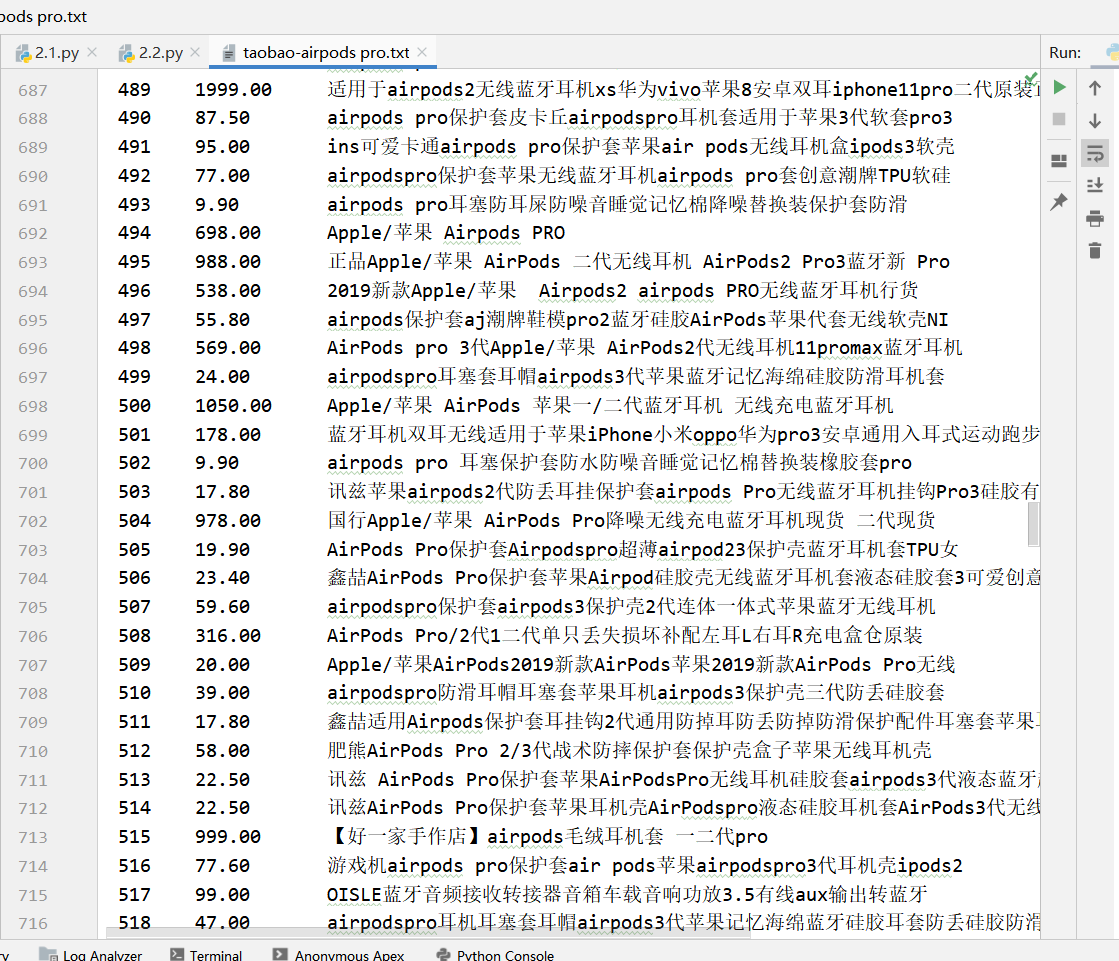
我爬取的是airpodspro的相关信息,爬取100页,具体的数据会存储到txt中
运行程序,成功

爬取的过程中出现了编码问题
1 | UnicodeEncodeError: 'gbk' codec can't encode character '\xae' in position 17: illegal multibyte sequence |
处理一下exception就好了

实验2.2-用srapy框架爬取任意网站的内容
要求:(不少于50条)
介绍
1.Scrapy与request
- 相同点:两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线 两者可用性都好,文档丰富,入门简单 两者都没有处理js、提交表单、应对验证码等功能(可扩展)
- 不同点:
- Requests 页面级爬虫,功能库,并发性考虑不足,性能较差,重点在于页面下载。定制灵活,上手十分简单 。
- Scrapy
网站级爬虫 框架,并发性好,性能较高, 重点在于爬虫结构。 一般定制灵活,深度定制困难, 入门稍难。
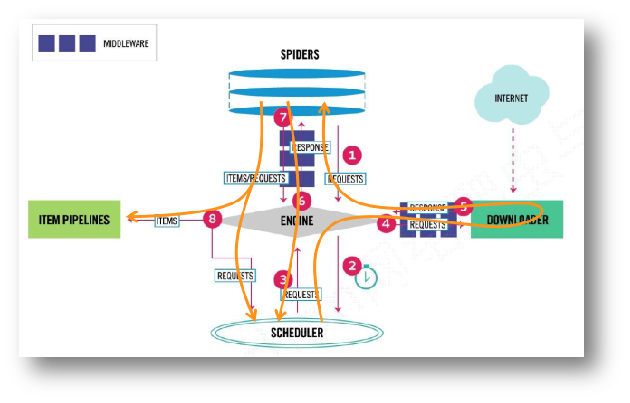
1 | Engine从Spider处获得爬取请求(Request) |
2.安装
安装lxml: pip install lxml
下载对应版本的Twisted
我下面的方法没成功,是在pycharm下下载的
%%%%%%%%%%%%%%%%%%%%
++++++++++++++++++++++++
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
pip3 install C:\Users\78290\Desktop\Twisted-20.3.0-cp38-cp38-win_amd64.whl
(下载好的twisted模块的whl文件路径)
%%%%%%%%%%%%%%%%%%
安装scrapy:pip install scrapy
安装关联模块pypiwin32:pip install pypiwin32
3.创建一个scrapy
Scrapy常用命令
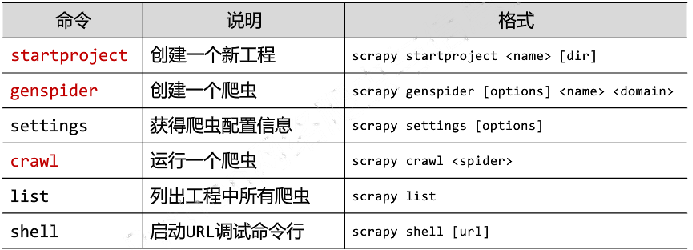
1.创建项目:
1 | scrapy startproject tutorial |

2.定义Item
编辑 tutorial 目录中的 items.py 文件:
3.编写spider
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,必须继承 scrapy.Spider 类, 且定义三个属性:
- name: 用于区别Spider。 该名字必须是唯一的,不可以为不同的Spider设定相同的名字。
- start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
- parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
1 | 在项目中生成 spider 文件的两种方法: |
4.执行spider
进入项目的根目录,执行下列命令启动spider
1 | scrapy crawl w3school |
5.提取item
scrapy支持如下库
- Beautiful Soup
- Lxml
- Re
- Xpath
- CSS
豆瓣电影 top250
创建项目
1 | scrapy genspider douban_movie "douban_movie.com" |
进入spider新建spider
1 | cd douban |
项目结构
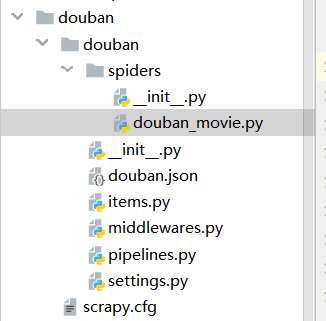
代码如下
douban_movie.py
1 | # -*- coding: utf-8 -*- |
items.py
1 | # -*- coding: utf-8 -*- |
pipelines.py
1 | # -*- coding: utf-8 -*- |
setting.py
1 | BOT_NAME = 'douban' |
启动
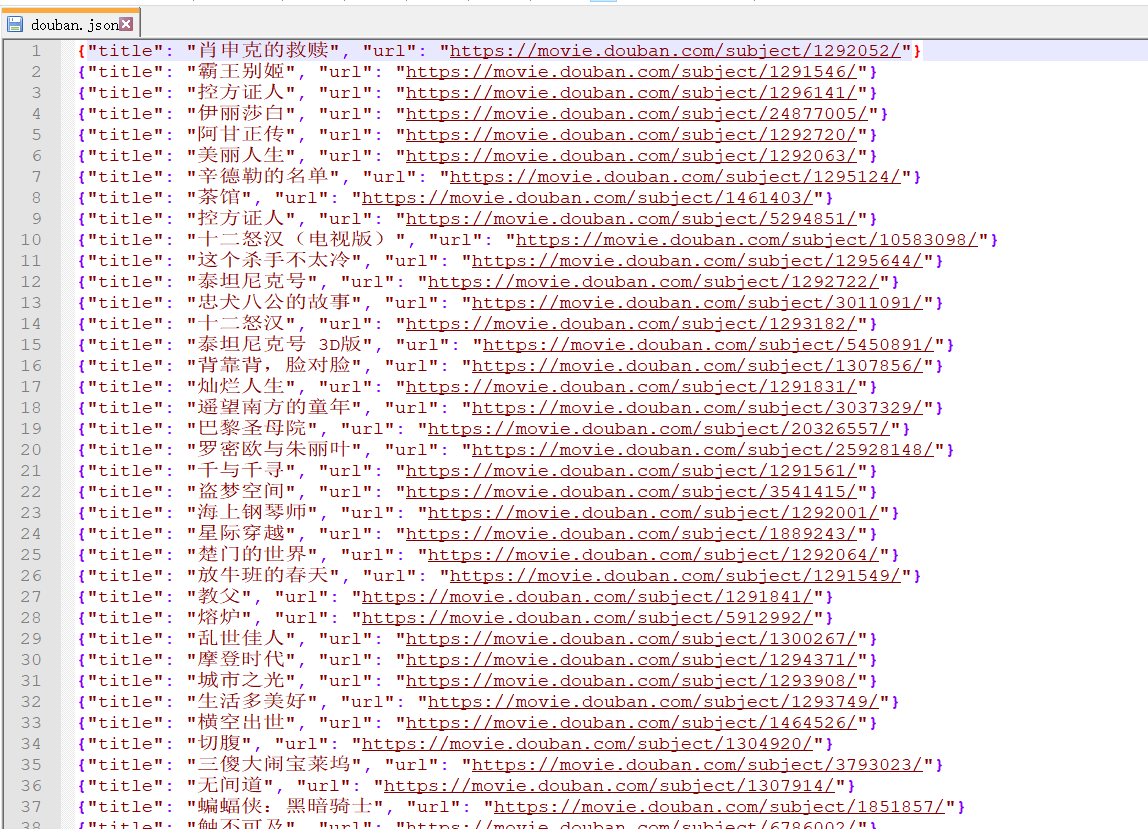
1 | scrapy crawl douban_movie |
成功 保存为douban.json
参考链接:
实验3-使用GooSeeker爬取数据
介绍
GooSeeker是一个采用云计算架构的网页数据抽取工具包,能根据用户的指导,从网页上抓取需要的文本,并输出按一定结构输出提取结果文件(XML文件)

实例-知乎热榜爬取
安装
首先从官方网站下载安装包,在主界面选择“下载爬虫”的下载方案比较方便。安装好软件后,新用户需要在集搜客网站上注册账号,用于之后登录集搜客软件。
1.制作采集规则
打开MS谋数机
输入目标抓取网站的网址,命名规则主题名。
第一步:在MS谋数机的“网址栏”,输入想要进行爬虫抓取的网页的网址,然后回车进行加载,可以在MS谋数机下方的“浏览器”窗口看到页面显示。
第二步:页面加载完后,在右边的“工作台”中的“命名主题”下方的“主题名”栏处输入自定义的主题名,这里我命名为“zhihu-rebang”,然后点击旁边的“查看”按钮,测试你起的名字是否已被占用,如果提示“该名可以使用”则命名成功。
2.新建整理箱
第一步:点击右方的“工作台”中的“创建规则”,点击“新建”按钮,在弹出的窗口中输入想要命名的整理箱名称。这里我命名为“rebang”。
第二步:在整理箱中添加抓取内容。右击整理箱名称选择“添加-包含”,这里我先添加“热榜名”,继续添加的话,右击“热榜名”选择“添加-其后”,添加“热榜简介”。
第三步:整理箱中必须有一个是“关键内容”,选择一个抓取内容设为“关键内容”,这里我吧“热榜名”勾选为“关键内容”。

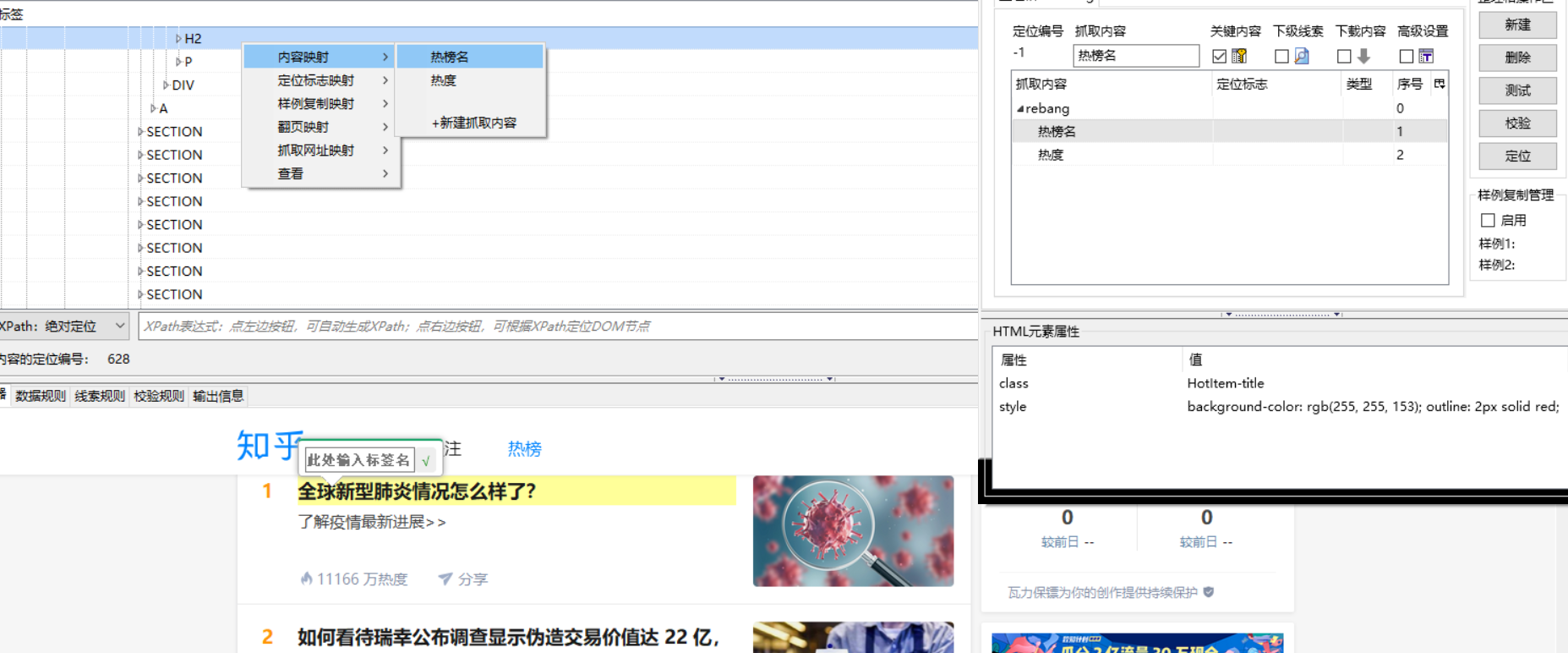
3.进行内容映射
第一步:在“浏览器”窗口中点击想要获取的内容,比如现在要获取哪个内容,就在那个区域进行鼠标点击,这时候MS谋数台会自动定位其在HTML中结点的位置。
第二步:展开一个节点,因为“热榜名”是一个H2所以找到H2标签。
第三步:右击这个text,选择“内容映射-热榜名”。
第四步:后面的内容映射同第三步。
4.使用样例复制
由于评论和评论之间是相同结构的数据,我们上一步只是完成了一个评论条目的抓取,想要抓取更多的评论就需要进行样例复制。
第一步:点击整理箱名称,即“rebang”。
第二步:勾选右侧方的“启用”,开启样例复制功能。
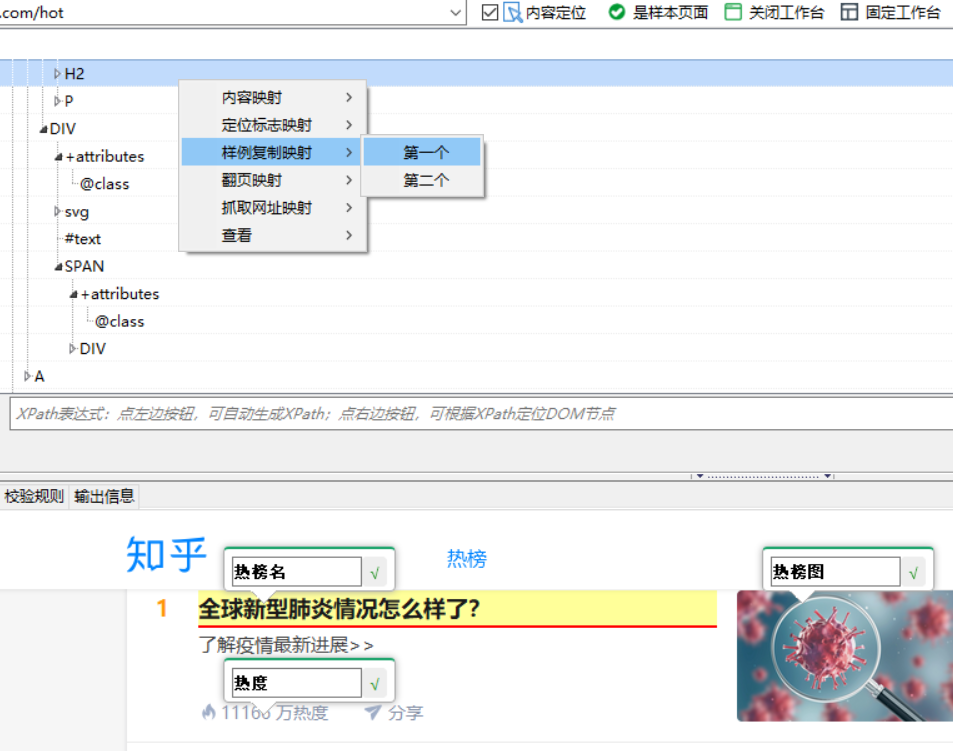
第三步:分别找到第一条热榜名和第二条热榜名对应的节点。
第四步:右击第一条评论对应结点,选择“样例复制映射–第一个”。
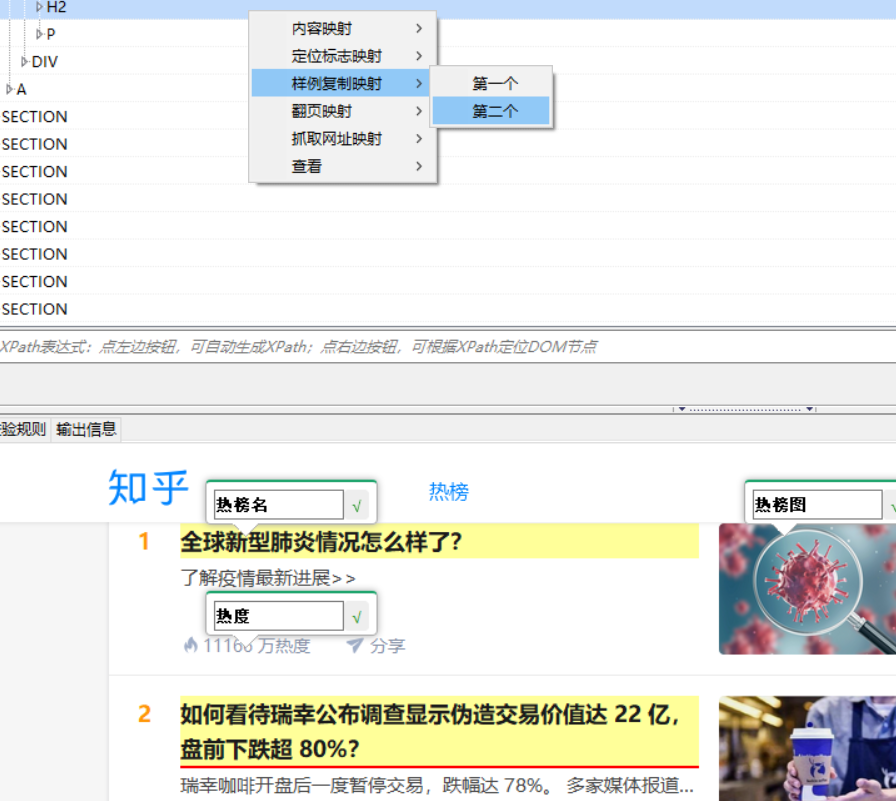
第五步:右击第二条评论对应结点,选择“样例复制映射–第二个”。
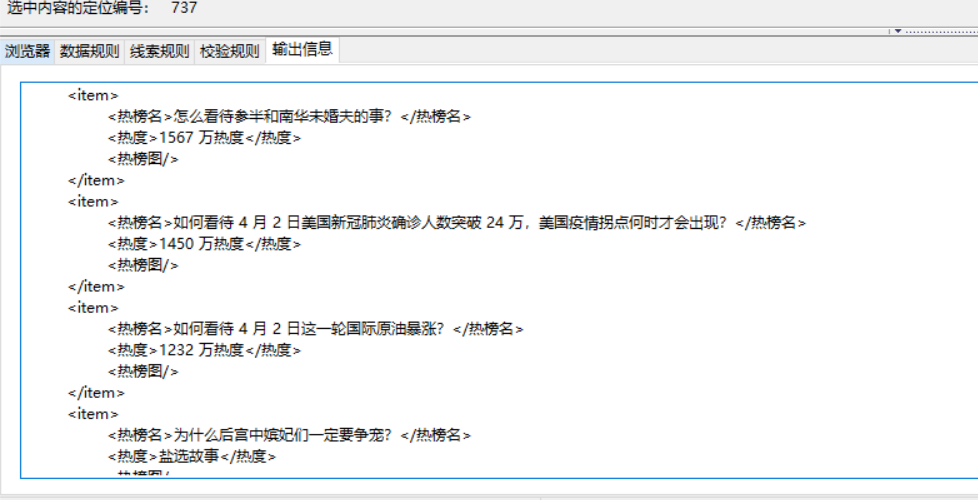
可以点击右侧的“测试”按钮对当前的规则进行测试,看到的结果是不是想要抓取的内容。
第二个样例复制映射
测试->输出
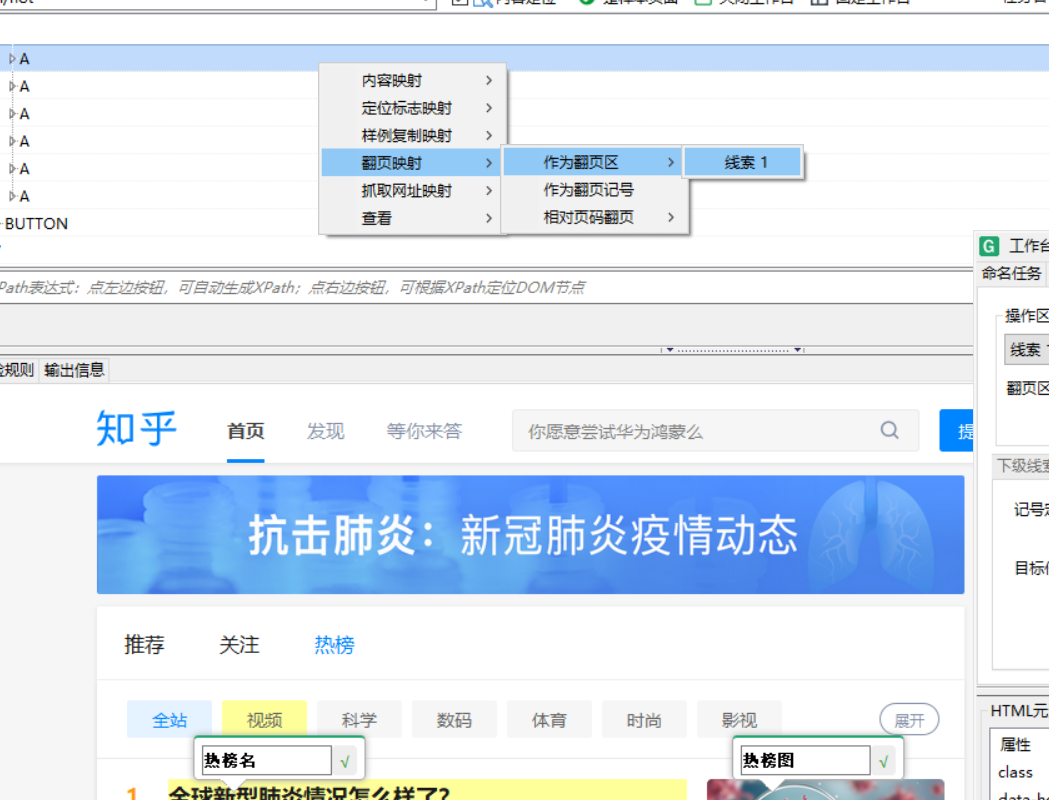
5.创建记号线索
由于评论有很多页,所以我们要解决抓取数据的时候翻页的问题,需要创建一个“记号线索”。
但是知乎热榜并没有下一页,所以暂时不用
6.MS打数机存规则
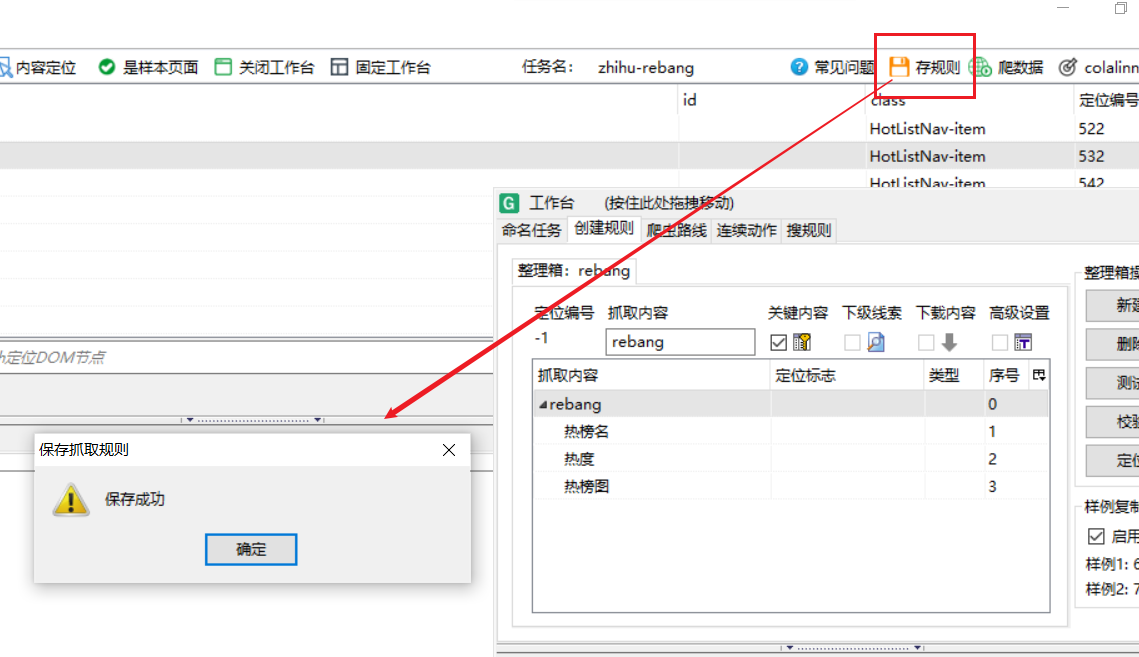
7.打开DS打数机爬取
在gooseeker里打开或MS数谋机中导航打开
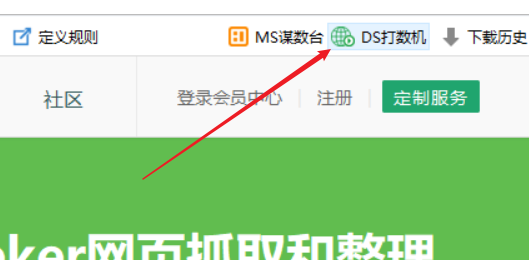
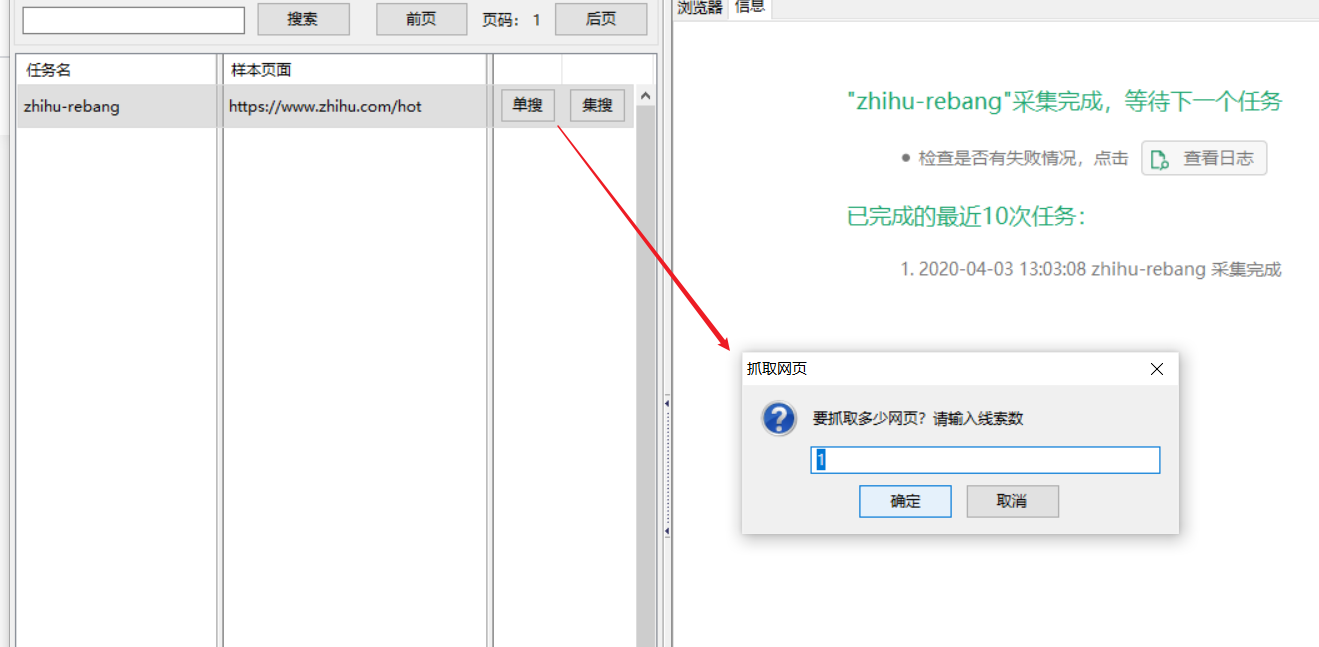
选择任务“zhihu-rebang”->单搜
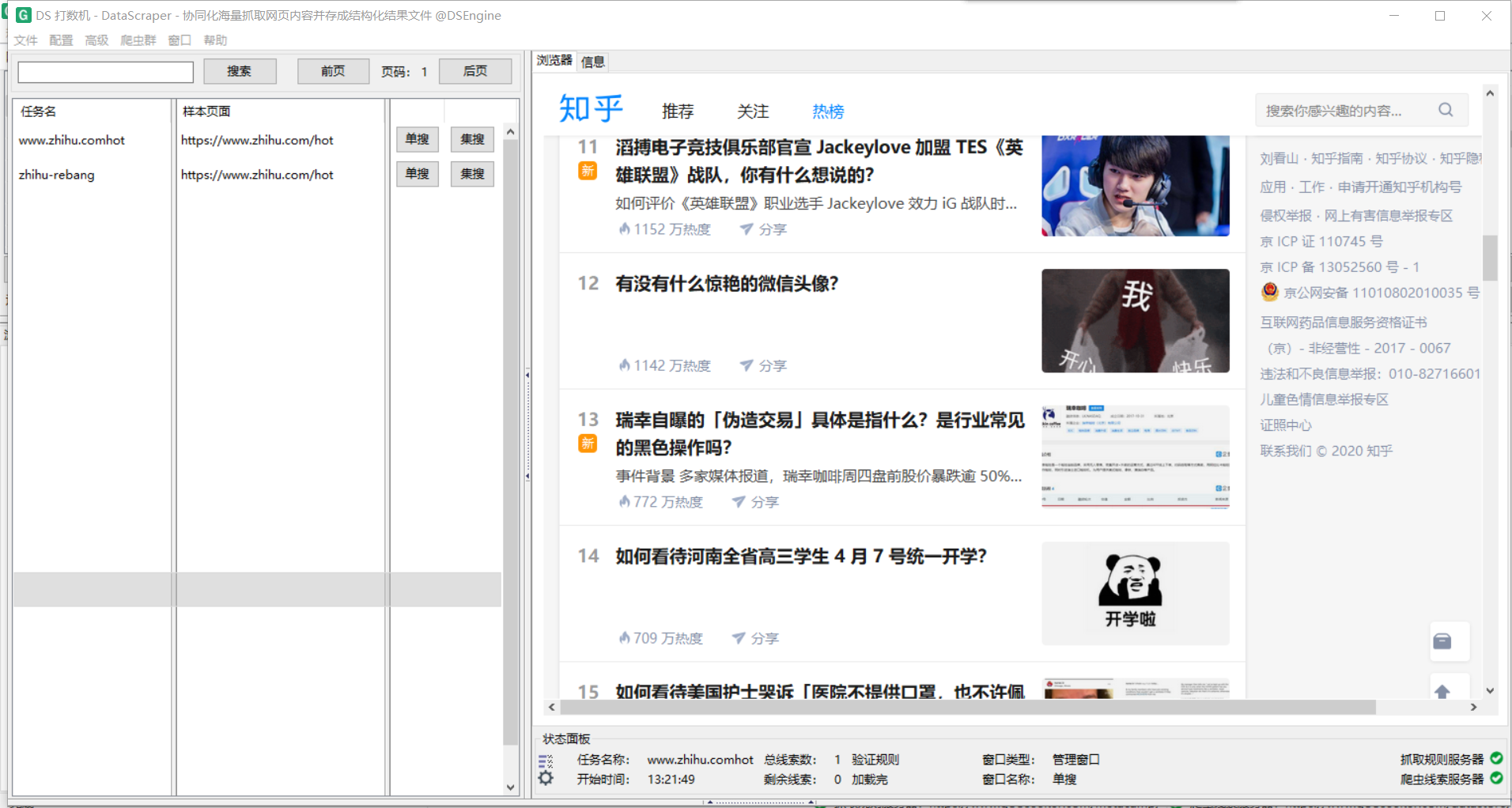
单搜完之后,数据默认存储在下面的路径
1 | C:\Users\用户名\DataScraperWorks\任务名 |
在爬取完后打开
8.导出xlsx数据
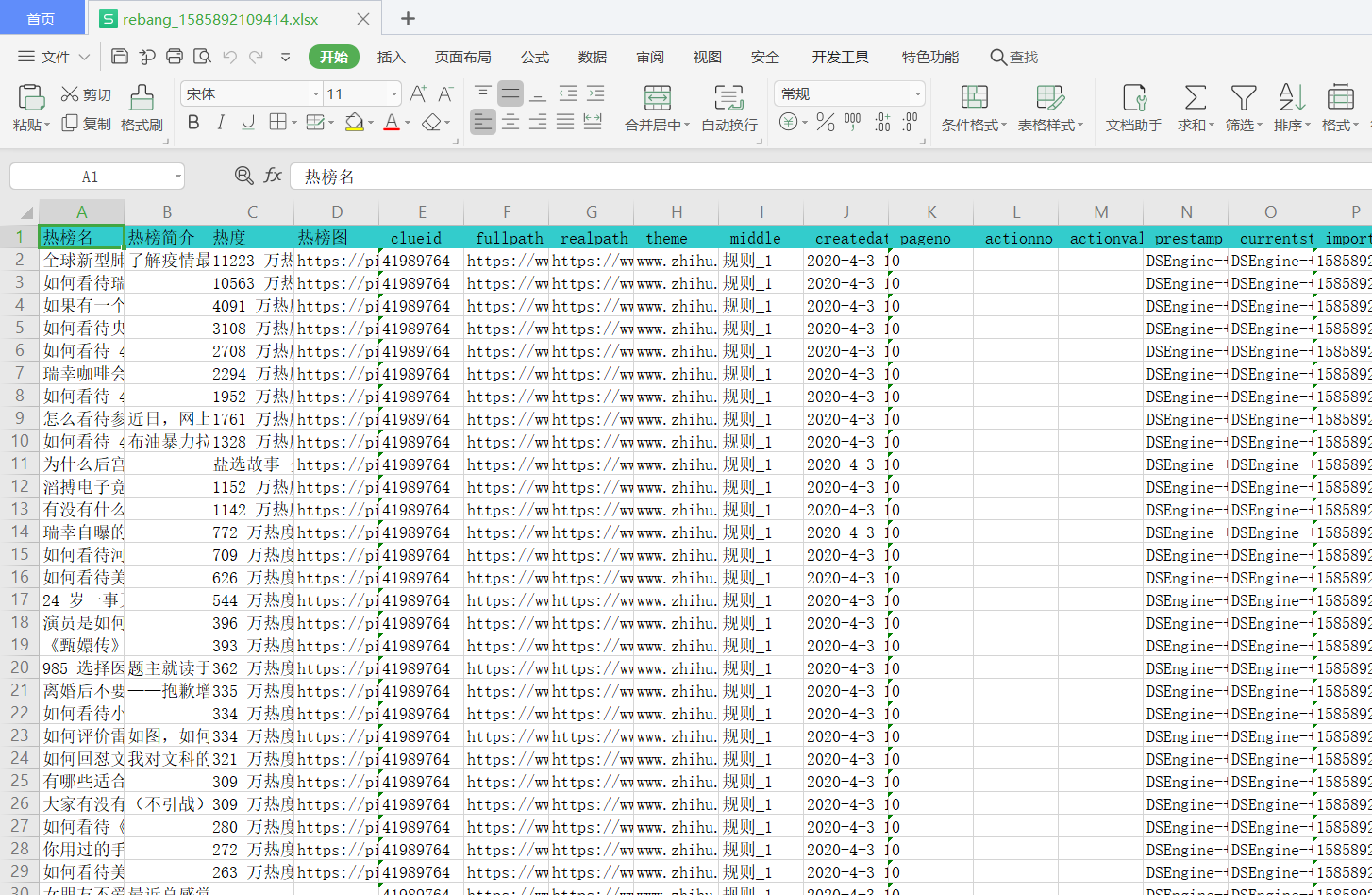
在会员中心、数据管理中导入存储在本地的爬取数据

导出为xlsx数据,成功!
参考链接:
https://www.jianshu.com/p/62bb53e07544
总结
这次的实验学到了爬虫的python相关库、工具,学习了正则式等知识
BeautifulSoup库这种自己操作的让我感觉比较轻松,但是srapy、gooseeker没有弄的太深,只学了皮毛。但是按scrap明显比较成熟,有各种配置可以使用,以后还是得学一手。
在学爬虫之前一直对网络很恐惧,自己不能掌握它,后来学了计网,其实也不过如此。
总的来说这次实验基本都完成了,在学完计网之后虽然理解了原理,但是一直没有实操。这次的实验给了我很多场景去学习,学到了很多。