
[TOC]
实验环境
IDE:pycharm
python版本:anacoda->python3.7
实验1.1-分词与词向量化
背景介绍
1.分词
对于西方拼音语言来讲,词之间有明确的分解符,统计和使用语言模型非常直接,而对于中文,词之间没有明确的分界符。因此需要对句子分词后,才能做自然语言处理。
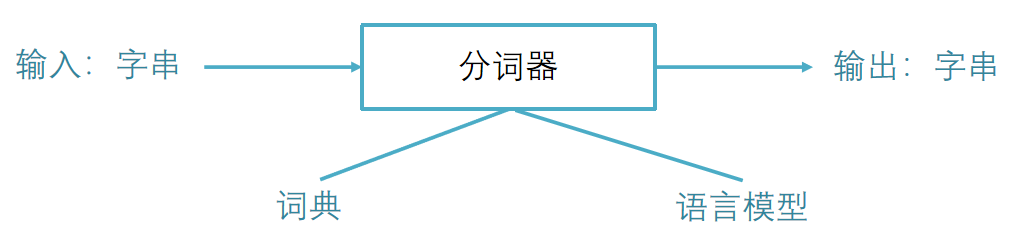
Python中分分词工具很多,包括盘古分词、Yaha分词、Jieba分词等。
这里选择Jieba(结巴)分词作为我们实验的工具
安装
1 | pip install jieba |
常用方法
1 | #导入自定义词典 |
2.词向量化
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation。
这种方法把每个词表示为一个很长的向量。
这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
举个例子:
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每个词都是茫茫 0 海中的一个 1。
!但是这种简单的方法有两个缺点:
1.维数灾难
2.“词汇鸿沟”现象:任意两个词之间都是孤立的,无法判断像“话筒”和“麦克”是同义词。
所以,我们需要词向量表示
新的词表示方法叫做Distributed Representation(分布式表示)。
这种方法表示词即用一个地位实数向量来表示一个词,如:[0.792, −0.177, −0.107, 0.109, −0.542, …]
语言进行词向量化,可使用Word2Vec。
word2vec是google的一个开源工具,能够根据输入的词的集合计算出词与词之间的距离。
它将term转换成向量形式,可以把对文本内容的处理简化为向量空间中的向量运算。
计算出向量空间上的相似度,来表示文本语义上的相似度。
word2vec计算的是余弦值,距离范围为0-1之间,值越大代表两个词关联度越高。
安装
1 | #安装带mkl的版本,下载wheel文件 |
为了减少安装中的繁琐,直接在anaconda进行集中安装,安装:
1 | pip install gensim |
实验
1.分词
代码如下,主要的都写了注释
1 | # encoding=utf-8 |
1、文档是windows格式,当我们按下键盘上的“回车键”时,输出的是CR和LF,即0d,0a两个字符。
2、文档是unix格式,当我们按下键盘上的“回车键”时,输出的LF,即0a一个字符。
3、文档是mac模式,当我们按下键盘上的“回车键”时,输出的是CR,即0d一个字符。
运行~
成功
分词结果如下
1.词向量化
代码如下,主要的都写了注释
1 | from gensim.models import word2vec |
运行
模型跑成功
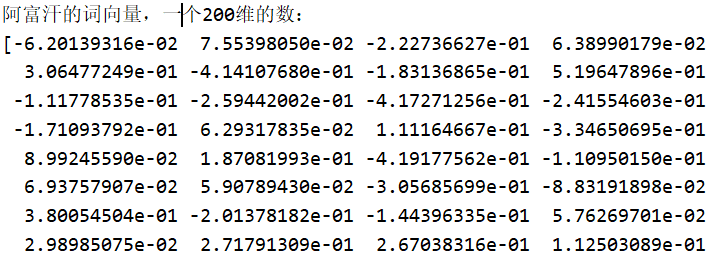
- 阿富汗的词向量,一个200维的数:
- 争端、冲突这两个词的相关程度:

- 输出与“地区”相关度最高的20 个词:

- 法官 总统 部长 北纬 这四个词中最“不合群”的词

保存模型

实验1.2-自选词典数据语料库
1.选择词典数据语料库
- 在词典方面,我用搜狗的细胞词库
- 下载网络安全词典,使用搜狗细胞词库转txt工具
- 在语料库方面,我选择BBC语料库
- 如图,在科技板块,搜索相关关键词
- 大概搜索了五个关键词(如病毒、蠕虫、网络安全等)。
- 然后根据其语料集存在的问题,进行数据清洗
选择词典数据语料库的结果如下
2.分词
代码与第一个实验基本一致
1 | def security_cut(): |
3.词向量化
代码与第一个实验基本一致
1 | # This Python file uses the following encoding: utf-8 |
词向量模型训练成功,测试的结果如下
病毒的词向量,一个200维的数:
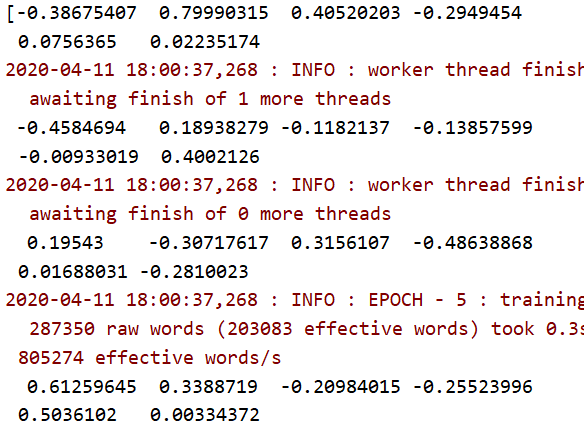
病毒、木马这两个词的相关程度:0.9492484
输出与“网络安全”相关度最高的20 个词:

病毒 木马 诺顿 蠕虫 这四个词中最“不合群”的词:诺顿
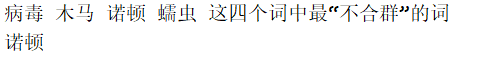
#coding = gbk
实验2-垃圾邮件的分类
原理
1.文本分类
文本分类就是在给定的分类体系下,让计算机根据给定文本的内容,将其判
别为事先确定的若干个文本类别中的某一类或某几类的过程。
一般来说,文本分类可以分为一下过程:
(1) 预处理:将原始语料格式化为同一格式,便于后续的统一处理;
(2) 索引:将文档分解为基本处理单元,同时降低后续处理的开销;
(3) 统计:词频统计,项(单词、概念)与分类的相关概率;
(4) 特征抽取:从文档中抽取出反映文档主题的特征;
(5) 分类器:分类器的训练;
(6) 评价:分类器的测试结果分析。
典型的分类算法包括Rocchio算法、朴素贝叶斯分类算法、K-近邻算法、决
策树算法、神经网络算法和支持向量机算法等。
2.朴素贝叶斯分类算法
根据贝叶斯定理,利用先验概率和条件概率估算后验概率:
先验概率:事情还没有发生,那么这件事情发生的可能性的大小。
后验概率:事情已经发生,那么这件事情发生的原因是由某个因素引起的可能性的大小。

将该算法代入我们的垃圾邮件分类任务中之后,理论如下:
(1).概率计算
假设c0是正常邮件,c1是垃圾邮件。𝑝(𝑐0)表示在邮件数据集中,正常邮件的概率,𝑝(𝑐1)则表示垃圾邮件的概率,所以计数之后除以邮件总数即可。
x与y分别是邮件的两个特征,那么,当邮件有x和y两个特征时(因为两个概率的分母完全一样,因此在比较两者大小时可忽略分母。)
为正常邮件的概率为
𝑝(𝑐0/𝑥, 𝑦) =𝑝(𝑥, 𝑦/c0)*p(c0)为垃圾邮件的概率为
𝑝(𝑐1/𝑥, 𝑦) =𝑝(𝑥, 𝑦/c1)*p(c1)
(2).“朴素”——引入条件独立性假设
x和y的条件概率相互独立。𝑝(𝑥/𝑐𝑖)和𝑝(𝑦/𝑐𝑖)可以对数据进行计数而直接得出。
则条件概率𝑝(𝑥, 𝑦/ci)=𝑝(𝑥/c0)*𝑝(𝑦/ci)
即上述公式为𝑝(𝑐0/𝑥, 𝑦) =𝑝(𝑥, 𝑦/c0)*𝑝(c0)=𝑝(𝑥/c0)*𝑝(𝑦/ci)*p(c0)
(3).假设每个样本至少出现一次
由于条件独立性假设,需要对条件概率进行乘法运算,若某个样本不出现,即概率为0,则最后结果也为0。所以假设每个样本至少出现一次。
(4).将全部乘法运算改为log运算
在实际运算中,条件概率可能会很小,即接近于0,那么在乘法运算中很可能会有下溢出的问题。
3.实际的编码流程
在本实验中,实际的编码时,我们所需要做的事按顺序排列的如下:
网上选择一些中文常用的停用词。
读入spam(恶意)、ham(正常)邮件,用jieba.cut()分词,并且去除停用词,保存。
用jieba.analyse.extract_tags()分别提取两个文件的前50(或更多)常见词,合成为一个常见词list,作为我们的特征词向量features。
接下来,对spam、ham的分词结果进行特征词向量features的特征计算:
- 对每一封邮件,其特征词向量features全为1
- 统计其在features中每个词的出现次数
- 如果features出现一次,该项就加1
根据朴素贝叶斯定理计算spam、ham后验概率spam_vec\ham_vec
计算spam、ham各占总邮件数的概率p_spam、p_ham
计算待测试集的特征集向量test_vec
将
test_vec*spam_vec*p_spam与test_vec*ham_vec*p_ham相比,哪方概率大则该封测试邮件属于哪一类(为了避免正常邮件分为垃圾邮件,当概率相等时,判定为正常)
代码
- 网上选择一些中文常用的停用词。
读入spam(恶意)、ham(正常)邮件,用jieba.cut()分词,并且去除停用词,保存。
用jieba.analyse.extract_tags()分别提取两个文件的前50(或更多)常见词,合成为一个常见词list,作为我们的特征词向量features。
1 | def extract_tags_f(origin_file_name, target_file_name,number_of_item): |
- 接下来,对spam、ham的分词结果进行特征词向量features的特征计算:
- 对每一封邮件,其特征词向量features全为1
- 统计其在features中每个词的出现次数
- 如果features出现一次,该项就加1
1 | def calc_vec(ham,spam,features): |
- 根据朴素贝叶斯定理计算spam、ham后验概率spam_vec\ham_vec
1 | def traing_bayes(trainMatrix, trainCategory): # trainMatrix为所有邮件的矩阵表示,trainCategory为表示邮件类别的向量 |
- 计算spam、ham各占总邮件数的概率p_spam、p_ham
- 计算待测试集的特征集向量test_vec
- 将
test_vec*spam_vec*p_spam与test_vec*ham_vec*p_ham相比 - 哪方概率大则该封测试邮件属于哪一类(为了避免正常邮件分为垃圾邮件,当概率相等时,判定为正常)
1 | def test_classify(test,features,ham_vec,spam_vec,p_spam): |
main函数
1 | def main(): |
运行程序:
总结
朴素贝叶斯分类算法评价:
查准率(Precision)、查全率(召回率)(Recall)、准确率(Accuracy)
我们将算法预测的结果分成四种情况:
正确肯定(True Positive,TP):预测为真,实际为真
正确否定(True Negative,TN):预测为假,实际为真
错误肯定(False Positive,FP):预测为真,实际为假
错误否定(False Negative,FN):预测为假,实际为假
则:
查准率P=TP/(TP+FP)
查全率R=TP/(TP+FN)
准确率ACC=(TP+FN) / (TP+TN+FP+FN)
以下为去除重读词
1 | 去除重复词后特征项数为: 20 |
可以看到调和均值F趋近于极限了,再加特征项数也无用
如果不去除重读词,反而会好些,最好结果如下,特征项数为150
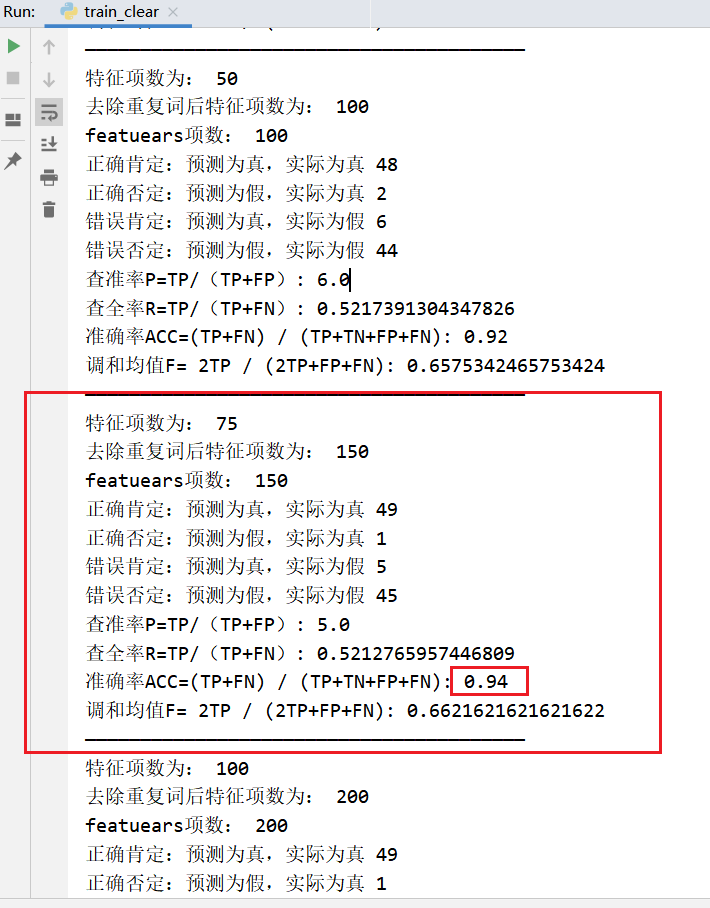
1 | 特征项数为: 75 |
错误的基本是如下6封,不过如果去除重复词那就不会有将正常邮件判断成错误邮件的情况。
1 | 第29封邮件是错误邮件————判断错误!————其实是正常邮件哒 |
其中70\73都比较特殊,其邮件字数都很少,难以分类成功

理论上来说,对于贝叶斯而言:
主要优点有:
1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
2)对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
主要缺点有:
1) 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
4)对输入数据的表达形式很敏感。
而综合实验:
对于邮件分类任务而言,贝叶斯确实蛮稳的,在如此少量的数据集中,有稳定的、有效的分类效率,对小规模的数据表现很好。
而其在这个数据集中的准确率ACC最高可达94%,基本无法再提高。
我个人认为原因主要有如下几点:
- 训练集不够多,不够贴近实际
- 测试集存在特殊情况,如邮件极短、邮件较独特等
- 用于训练的特征项数,我上面的实验已经得出了结论
总结
这次的实验还是收获很多的:
- 学会了使用jieba库进行分词,提取特征词
- 学会了使用gensim进行word2vec词向量话
- 最大的收获是,自己实操,对贝叶斯算法进行了一次深入的尝试,很愉悦~
- 对文本分类的流程、机器学习的理解更深了