
[TOC]
实验环境
IDE:pycharm
python版本:anacoda->python3.7
1、图像实验
1.1 背景介绍
本次实验,主要熟悉图像的python库操作,仿射变换的学习,以及图像的基本聚类分类方法。
(1)图像的基本知识
通常情况下,计算机中图像是一个三维数组,维度分别是高度、宽度和像素RGB值。
RGB色彩模式,即每个像素点的颜色由红(R)、绿(G)、蓝(B)组成,RGB三个颜色通道的变化和叠加得到各种颜色,其中每个通道值为0~255。
(2)库介绍
NumPy是一个开源的Python科学计算基础库。
N维数组对象:ndarray
- 数组对象可以去掉元素间运算所需的循环,使一维向量更像单个数据
- 设置专门的数组对象,经过优化,可以提升这类应用的运算速度
PIL库(Python Image Library)Python中图像处理最常用的库
PIL库是一个具有强大图像处理能力的第三方库。
PILLOW官方文档:https://pillow.readthedocs.io/en/latest/reference/Image.html
中文博客:http://blog.csdn.net/column/details/pythonpil.html?&page=1
OpenCV:是计算机视觉领域应用最广泛的开源工具包。
基于C/C++,支持Linux/Windows/MacOS/Android/iOS,并提供了Python,Matlab和Java等语言的接口,因为其丰富的接口,优秀的性能和商业友好的使用许可,不管是学术界还是业界中都非常受欢迎。OpenCV旨在提供一个用于计算机视觉的科研和商业应用的高性能通用库。
Anaconda命令行安装:
1
conda install --channel https://conda.anaconda.org/menpo opencv3
(3)图像的基本操作
图像的表示
1.将彩色RGB图片变为黑白(灰度)图片
灰度转换公式:L = R * 299/1000 + G * 587/1000+ B * 114/1000
PIL中,灰度表示模式为L模式,它的每个像素用8个bit表示,0表示黑,255表示白,其他数字表示不同的灰度。
1 | from PIL import Image |

2.将彩色RGB图片变为“底片”模式
PIL中,当需要更个性化的图片时,可配合使用numpy,对图像中的数据进行操作将原图以灰度打开后,取反码(b=255-a)
1 | from PIL import Image |

3.滤波器提取图片的信息
PIL的ImageFilter模块提供了滤波器相关定义,这些滤波器主要用于Image类的filter()方法。
例如,提取图片的轮廓信息:使用ImageFilter.CONTOU
1 | from PIL import Image |

4.图片读、写和显示操作
1 | import numpy as np |
结果:
1 | (512, 512, 3) |
5.图像缩放
cv2.resize(src, dsize, dst, fx=0, fy=0, interpolation=INTER_LINEAR )
1.2 图像的仿射变换之图像缩放
仿射变换原理:
在仿射变换中,原始图像中的所有平行线仍将在输出图像中平行。
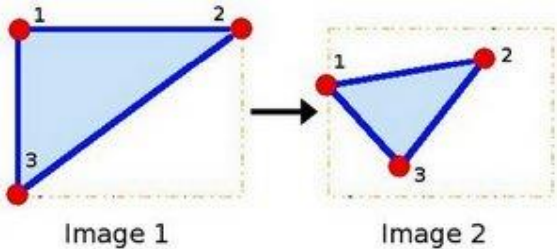
为了找到变换矩阵,我们需要输入图像中的三个点及其在输出图像中的相应位置。
仿射变换矩阵:
一个任意的仿射变换都能表示为 乘以一个矩阵 (线性变换) 接着再 加上一个向量 (平移).
- 旋转 (线性变换) 、平移 (向量加) 、缩放操作 (线性变换)
我们通常使用 2 x 3 矩阵来表示仿射变换.其中左边的2×2子矩阵是线性变换矩阵,右边的2×1的
两项是平移项:
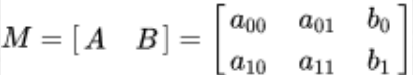
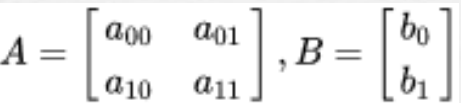
宽度方向是x,高度方向是y,坐标的顺序和图像像素对应下标一致。
所以原点的位置不是左下角而是左上角,y的方向也不是向上,而是向下。
对于图像上的任一位置(x,y),仿射变换执行的是如下的操作:
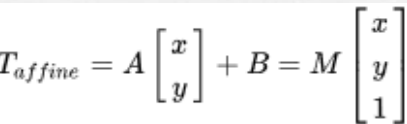
使用cv.getAffineTransform()将创建一个2x3矩阵,将该矩阵传递给cv.warpAffine()得到结果。
仿射变换进行图像缩放,代码如下
1 | # -*- coding: UTF-8 -*- |
结果如下:
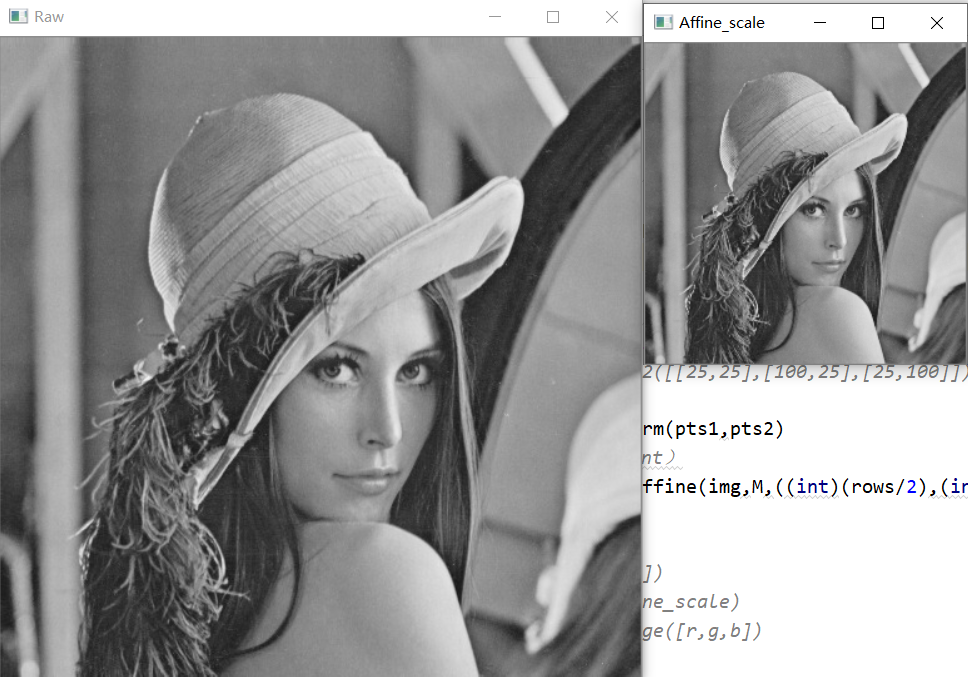
1.3 图像的透视变换(空间变换)
对于透视变换,需要一个3x3变换矩阵。在转换之后,直线仍将保持笔直。
要找到此变换矩阵,输入图像上需要4个点,输出图像上需要相应的。在这4个点中,其中3个不应该共线。
通过函数cv2.getPerspectiveTransform找到变换矩阵,将该矩阵传递给cv2.warpPerspective得到结果。
Tips:
仿射变换和透视变换更直观的叫法可以叫做“平面变换”和“空间变换”或者“二维坐标变换”和“三维坐标变换”。
从另一个角度也能说明三维变换和二维变换的意思,仿射变换的方程组有6个未知数,所以要求解就需要找到3组映射点,三个点刚好确定一个平面。透视变换的方程组有8个未知数,所以要求解就需要找到4组映射点,四个点就刚好确定了一个三维空间。
参考资料:
opencv python 图像缩放/图像平移/图像旋转/仿射变换/透视变换
代码:
1 | import cv2 |
结果如下:
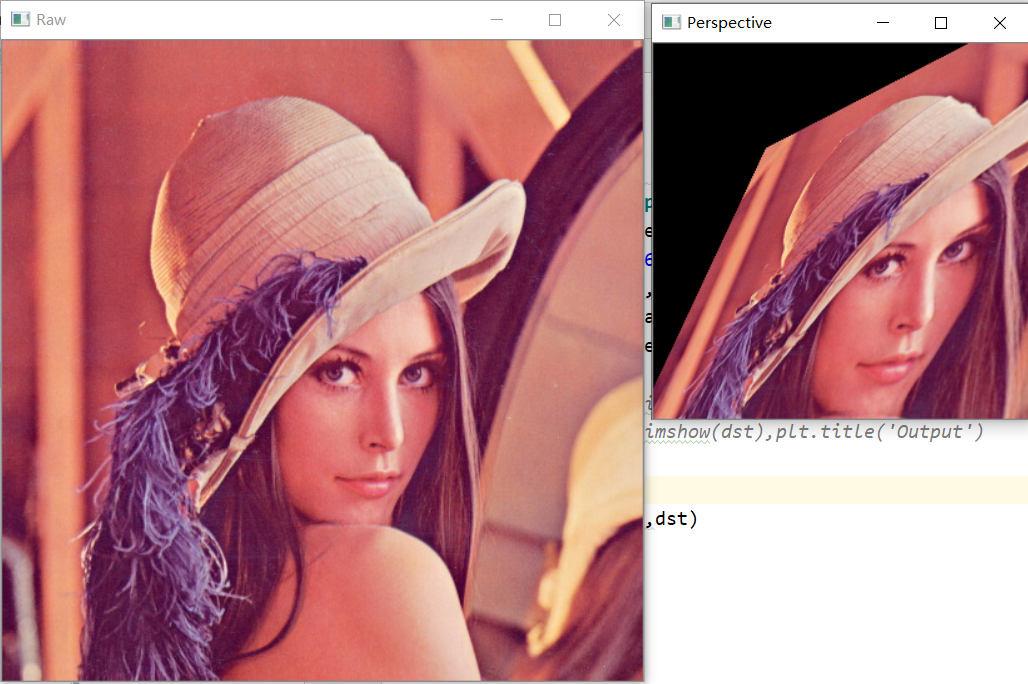
1.4 通过HOG特征来分类——OCR
OCR:
(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。
一般流程如下:
图像文件输入 → 图像特征提取 → 分类器训练 → 预测 → 识别结果输出→ 计算正确率 → …
HOG方向梯度直方图:
(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。HOG特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。
HOG步骤如下:
1 | HOG特征提取方法就是将一个image(你要检测的目标或者扫描窗口): |
这次实验用的是一张图的数据集(digits.png)来训练:

原代码如下:
1 | #!/usr/bin/env python |
训练结果如下:
其中,白色的数字为分类识别成功,红色的为识别错误

1.5 HOG特征,自找数据集进行测试
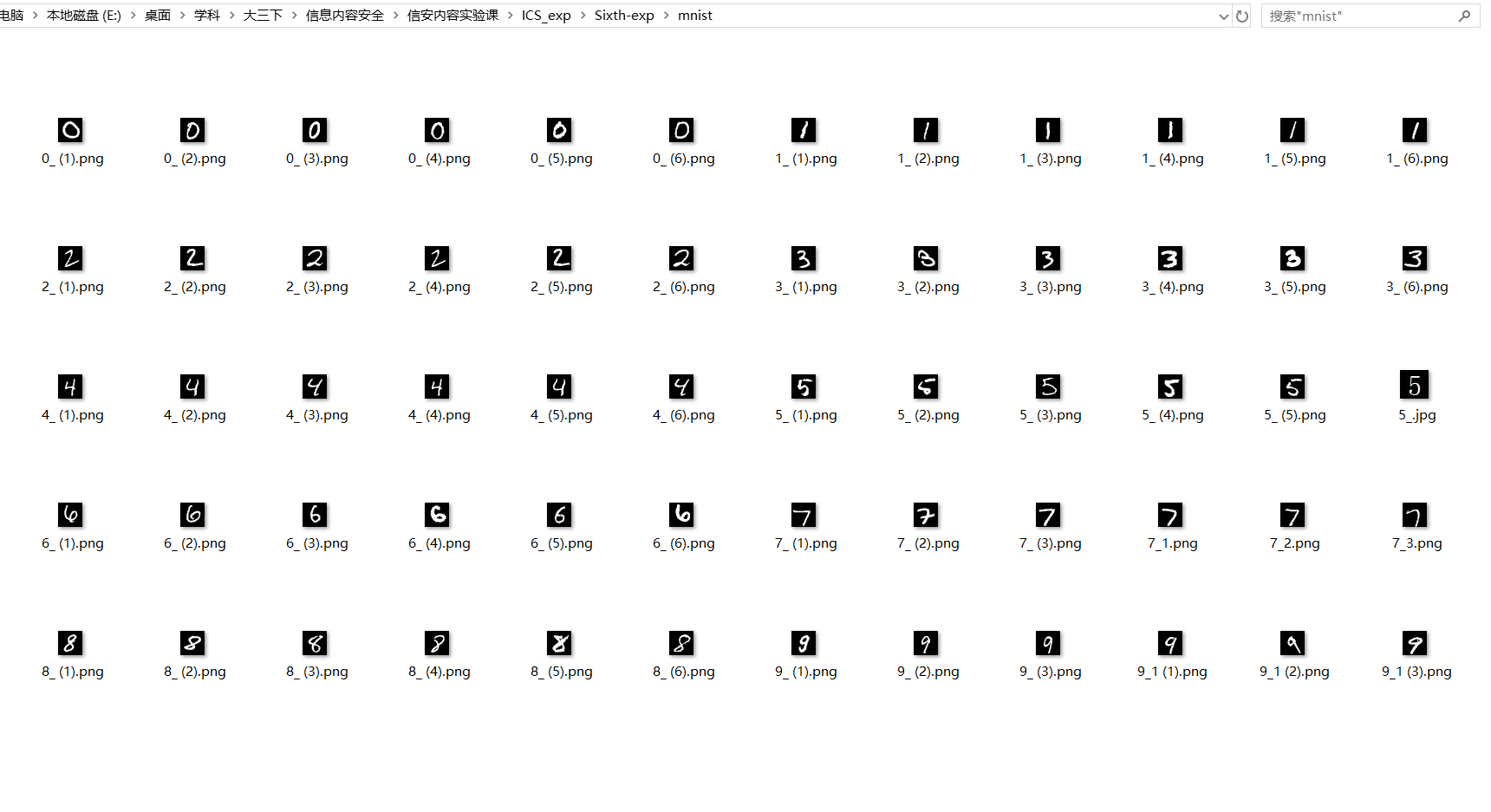
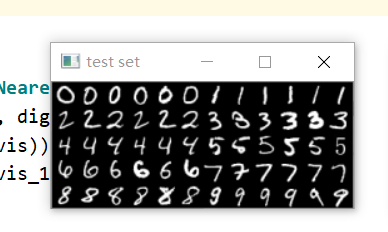
这里我选择了mnist的图、以及word做的一些图混合来进行测试:
mnist的图像大小都是28 * 28,word做的也不是20*20,我们用仿射变换来进行缩小为 20 * 20
数据集,每一种数字有6个,总共有6 * 10=60张图:
其中有个复杂的点,数据结构的问题:
1 | # resp = model.predict(samples) |
代码:
1 | import cv2 as cv |
结果:
可以看到,OCR效果还是不错的

2、音频实验
2.1 背景介绍
本节实验课,实践音频的相关操作和库,以及一些基本特征的提取。
使用了实验自带的音频
第一个实验(读取音频信息)用到的库:
音频库:wave 库 https://docs.python.org/3/library/wave.html
绘图库:pylab库,这是 Matplotlib 和Ipython提供的一个模块,提供了类似Matlab的语法
Matplotlib是一个Python的图形框架,类似于MATLAB,同时还可以使用内嵌的latex引擎绘制的数学公式。
LibROSA是python用于音乐、音频分析的一个工具包。官方文档:http://librosa.github.io/librosa/
第二个实验(读取音频特征)用到的库:
安装LibROSA :
windows命令行下pip install librosa
或anaconda命令行下conda install -c conda-forge librosa
LibROSA需要ffmpeg支持(用于音频和视频多种格式的录影、转换、流功能)
安装ffmpeg:
2.2 使用wave读取音频文件的信息
- 采样率
外界的声音都是模拟信号,在数字设备中A/D转化成为了由0、1表示的数字信号后被储存下来。数字信号都是离散的,所以采样率是指一秒钟采样的次数,采样率越高,还原的声音也就越真实。由于人耳听觉范围是20Hz~20kHz,根据香农采样定理(也叫奈奎斯特采样定理),理论上来说采样率大于40kHz的音频格式都可以称之为无损格式。 - *位深度 *
若要尽可能精确地还原声音,只有高采样率是不够的。描述一个采样点,横轴(时间)代表采样率,纵轴(幅度)代表位深度。 - 码率
在无损无压缩格式中(如.wav),码率=采样率x位深度x声道数。在有损压缩中(如.mp3)码率便不等于这个公式了,因为原始信息已经被破坏。 - 奈奎斯特采样定律:在进行模拟/数字信号的转换过程中,当采样频率fs.max大于信号中最高频率fmax的2倍时(fs.max>2fmax),采样之后的数字信号完整地保留了原始信号中的信息。
- 人耳听音频率范围: 20Hz~20kHz标准格式化的WAV文件和CD格式一样,采样频率为44.1K。
- 无损编码: 能够由编码后的数据完全无误地恢复原始信号采样值。常见的无损编码格式:APE、FLAC。
- 有损编码: 根据人耳对不同频率的声音感知敏感度不同,在压缩过程中损失一部分音质以换取更高的压缩比,由于编码过程中有信息的损失,无法完全恢复原始信号。
代码如下,说明已在代码中详细注释标出:
1 | # -*- coding: UTF-8 -*- |
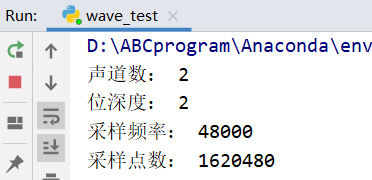
音频基本信息如下所示:
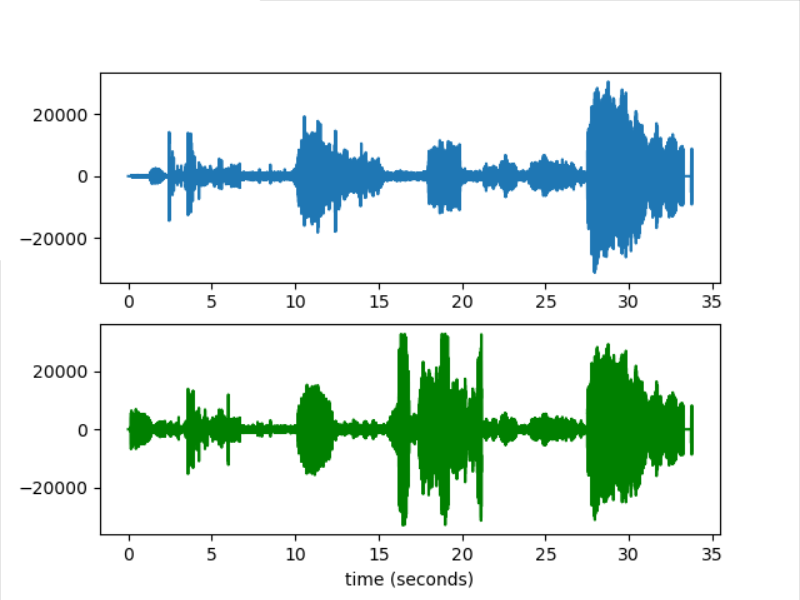
音频波形图:
蓝色部分为声道1(左声道),绿色部分为声道2(右声道)横轴为时间、纵轴为幅度的量化值:
2.3 使用LibROSA分别计算音频的MFCC和Chroma特征
每个音频信号都包含许多特征。但是,我们必须提取与我们试图解决的问题相关的特征。提取要使用它们进行分析的特征的过程称为特征提取,让我们详细研究一些特征。
音频特征基础:
谐波、冲击源分离(Harmonic Percussive Source Separation, HPSS)
一般而言,音乐信号在频谱图通常呈面两种形式分布,一种是沿时间轴连续平滑分布,另一种是沿频率轴连续平滑分布,通常将这两种分布的音源分别称作谐波源和冲击源。乐器可大致分为管弦乐器和打击乐器。管弦乐器产生的音源一般舒缓,音与音之间连续衔接,且频谱图上表现为平滑的包络,常见的管弦乐器有笛子、筝、小提琴、钢琴(钢琴虽不是严格意义上的管弦乐器,但其音源的频谱具有管弦乐音源的特征,因此这里将其归为一类)等。与之相反,打击乐器产生的音源一般有强烈的节奏感,音与音之间有较大的跨度在频谱图上表现为垂直包络,常见的打击乐器有鼓、木琴、小军鼓、锣等。因此在频谱图上,将管弦乐所产生的音源通常称之为谐波源,打击乐产生的音源通常称之为冲击源。谐波源通常包含固定音调,能在频谱上形成一系列平滑的瞬时包络,因此在时间轴方向上是平滑连续的,在频率轴方向上间断的;反之,冲击源一般集中在较短时间内,在频谱上形成一系列垂直的宽带谱包络,因此在时间轴方向上是间断的,在频率轴方向上是平滑连续的。
在计算音频特征时,会根据这两种信号的不同特点,进行分离后分别进行特征计算。比如chroma特征就只使用了谐波源作为源数据
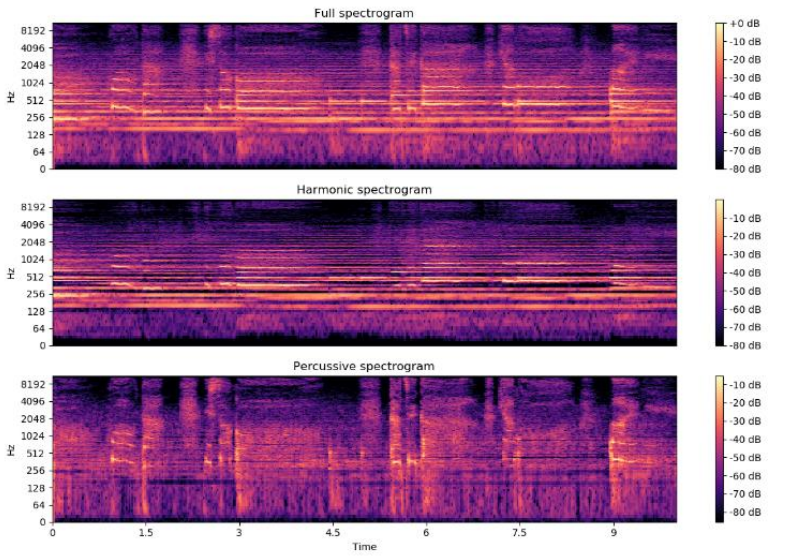
音频特征:
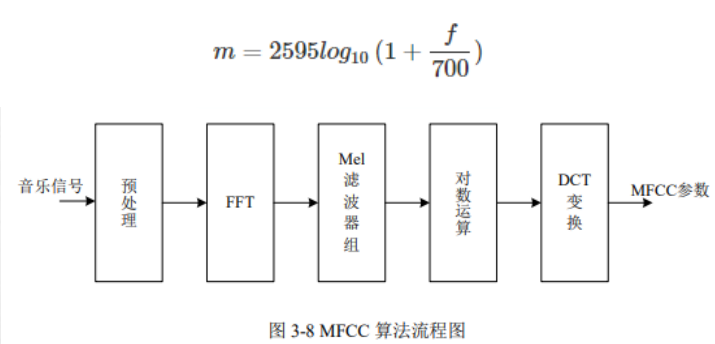
MFCC(Mel-frequency cepstral coefficients)
梅尔频率倒谱系数。梅尔频率是基于人耳听觉特性提出来的, 它与Hz频率成非线性对应关系。
当频率在1000Hz以下时,人耳的听觉能力与声音频率呈线性增长,当频率在1000Hz以上时,与声音的频率呈对数分布。梅尔频率倒谱系数(MFCC)则是利用它们之间的这种关系,计算得到的Hz频谱特征。主要用于语音数据特征提取和降低运算维度。
Chroma色度特征是色度向量(Chroma Vector)和色度图谱(Chromagram)的统称。色度向量是一个含有12个元素的向量,这些元素分别代表一段时间(如1帧)内12个音级中的能量,不同八度的同一音级能量累加,色度图谱则是色度向量的序列。色度特征的计算,参考:Automatic Chord Estimation from Audio: A R
eview of the State of the Art,过程如下图:
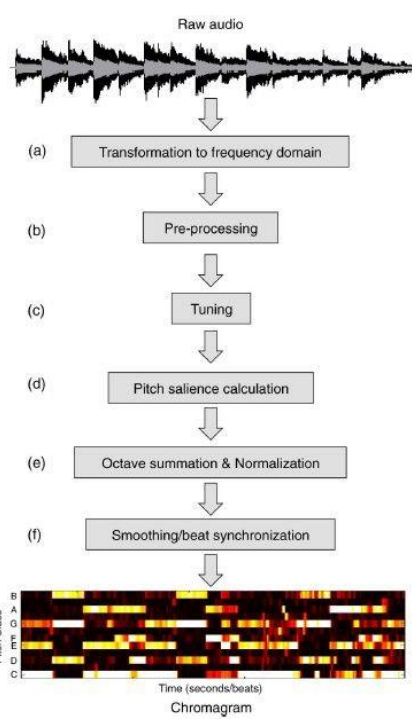
提取MFCC和Chroma
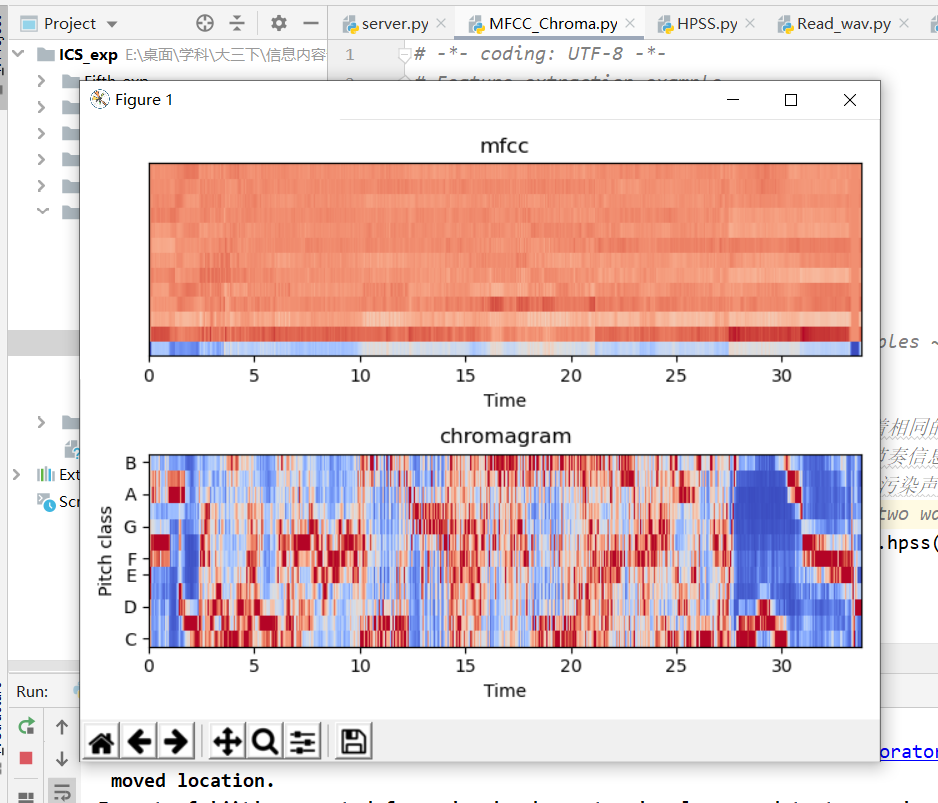
提取MFCC和Chroma的代码如下:
1 | # -*- coding: UTF-8 -*- |
如下为我们的mfcc和chroma的特征图
2.4 提取过零率特征
过零率(zero crossing rate)是一个信号符号变化的比率,即,在每帧中,语音信号从正变为负或从负变为正的次数。 这个特征已在语音识别和音乐信息检索领域得到广泛使用,通常对类似金属、摇滚等高冲击性的声音的具有更高的价值。
该特征在语音识别和音乐信息检索中都被大量使用。对于像金属和岩石那样的高冲击声,它通常具有更高的值。让我们计算示例音频片段的过零率。
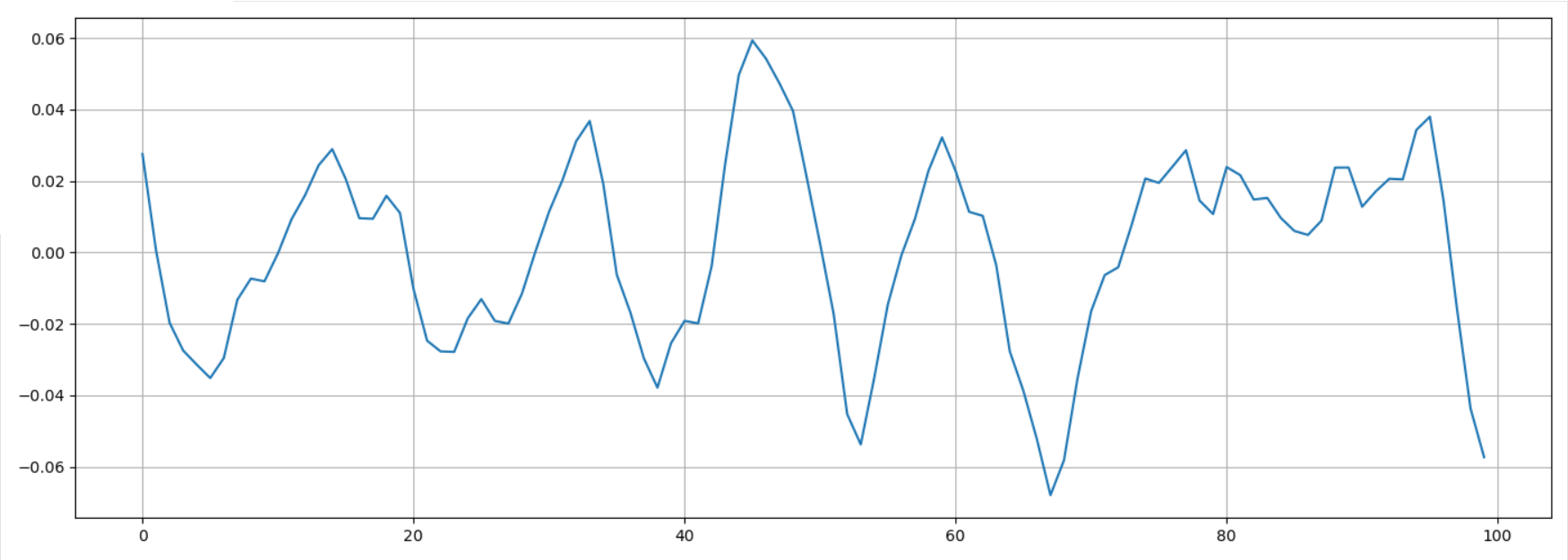
1 | # -*- coding: UTF-8 -*- |
在这段区间(9000~9100)有11个过零点
2.5 提取光谱质心特征
光谱质心(Spectral Centroid)指示声音的“质心”位于何处,并按照声音的频率的加权平均值来加以计算。 假设现有两首歌曲,一首是蓝调歌曲,另一首是金属歌曲。现在,与同等长度的蓝调歌曲相比,金属歌曲在接近尾声位置的频率更高。所以蓝调歌曲的频谱质心会在频谱偏中间的位置,而金属歌曲的频谱质心则靠近频谱末端。
librosa.feature.spectral_centroid 计算信号中每帧的光谱质心:
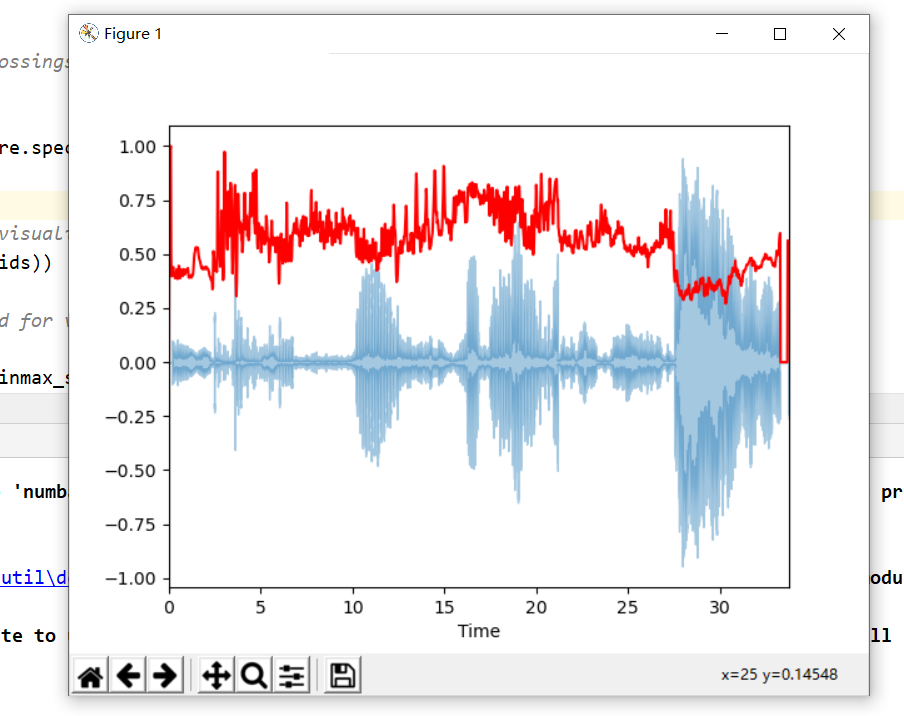
1 | # -*- coding: UTF-8 -*- |
参考资料:
LIBROSA处理音频信号 https://www.freesion.com/article/4795221829/
3、总结
- 这次实验挺有趣的,难度也适中。
- 大多数时候出错,都是api不熟悉导致的,多看多敲就好了。
- 图像处理部分的透视变化、numpy的熟悉、HOG特征的计算、KNN、SVM聚类的学习。音频部分对音频特征和参数的介绍等等,学到了很多东西。
- 但是,信息数据处理才是刚刚入了一点点门,还得继续努力才是。