概述1——排序,算法复杂度
二分搜索


合并排序 Θ(nlog^n^)


选择排序 Θ(n^2^)

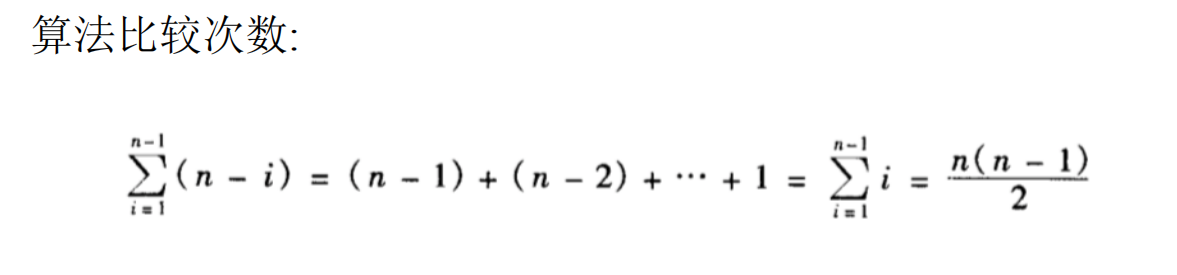
插入排序 Θ(n^2^)


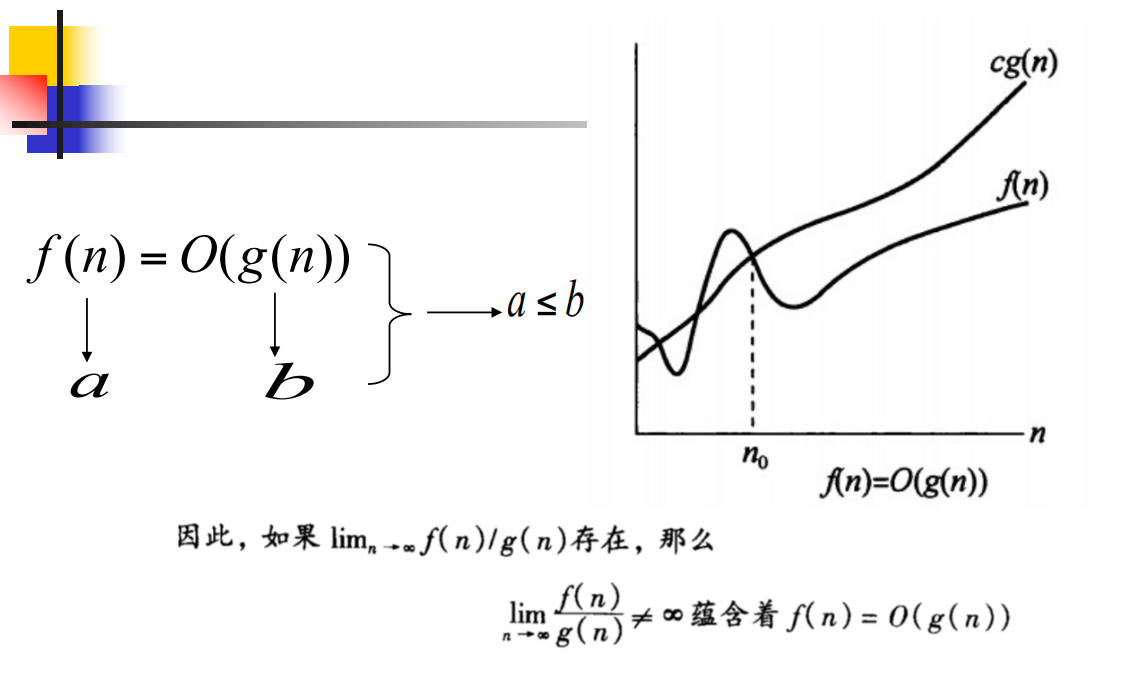
O 上界 ✍

不等于∞,其实就是当n趋近于无穷时,f(n)不大于cg(n)
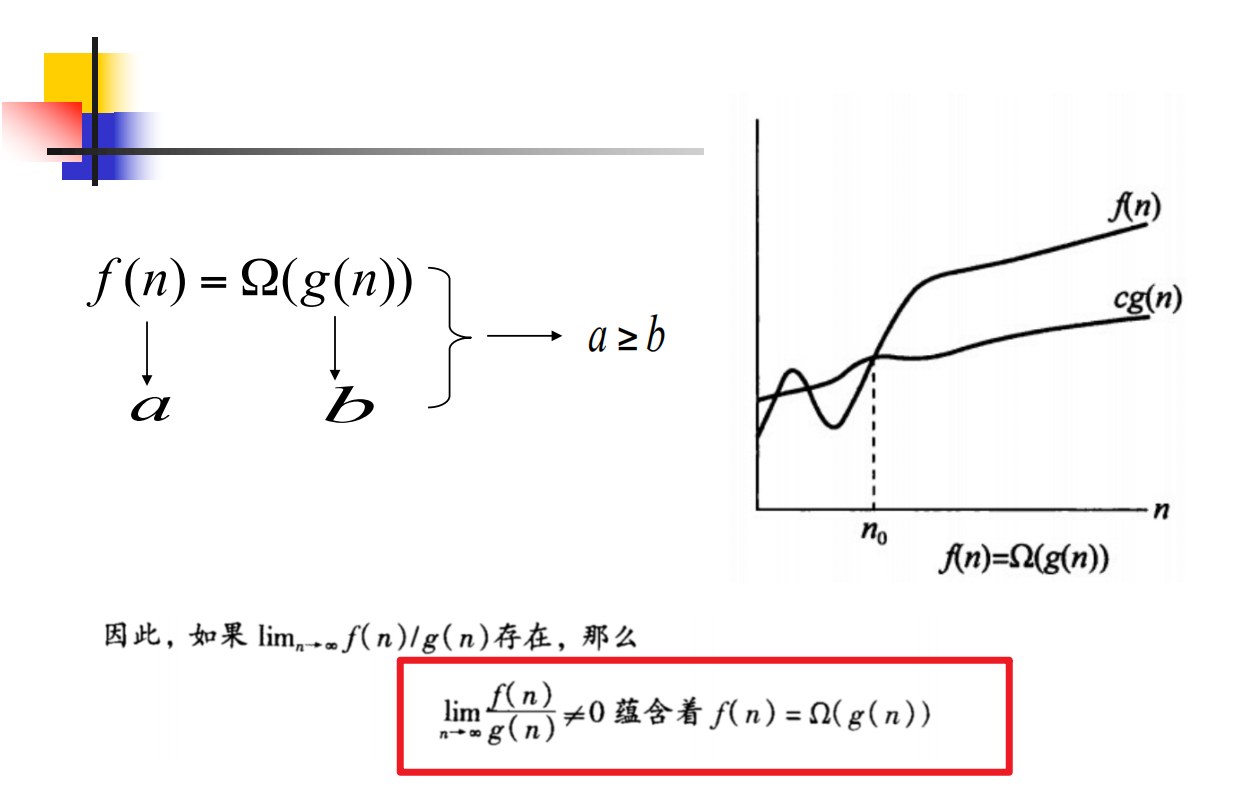
Ω下界

不等于0,其实就是当n趋近于无穷时,f(n)仍大于cg(n)
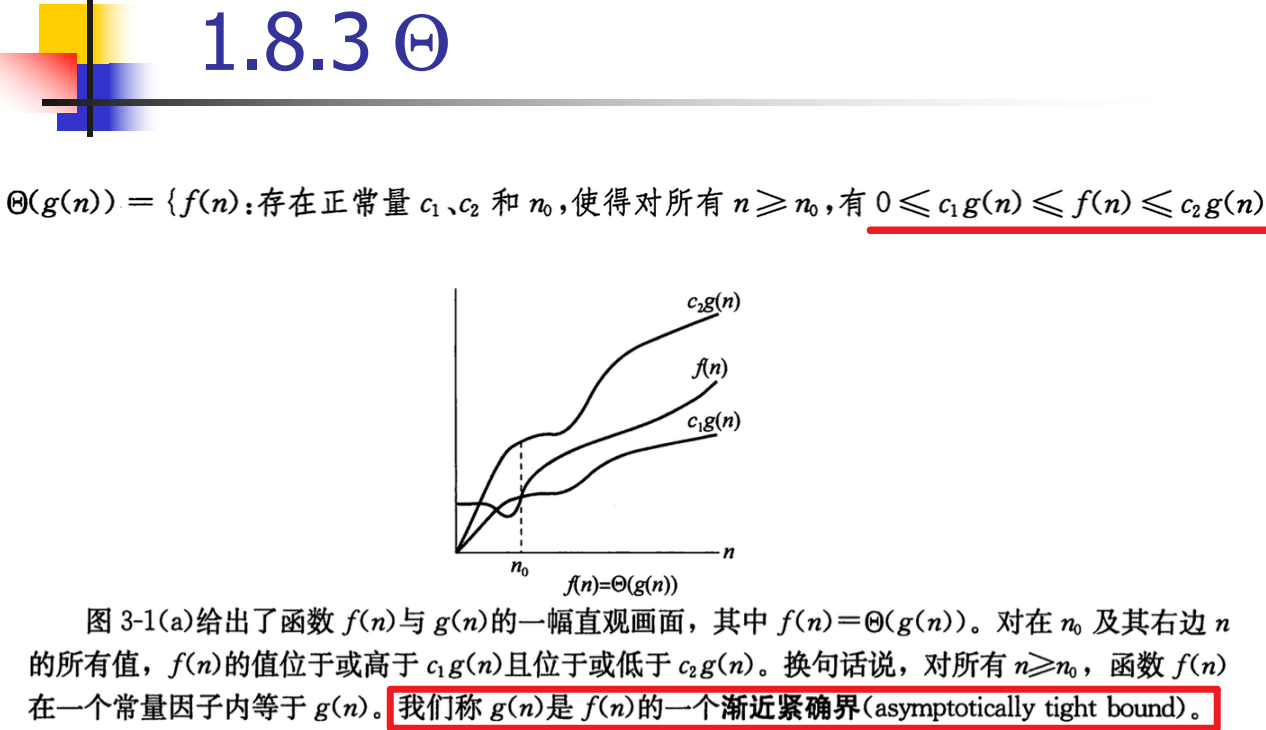
Θ紧确界

o上界
等于0,其实就是当n趋近于无穷时,f(n)远远小于cg(n)


性质
- 传递性
- 自反性
- 对称性
- 倒置对称性
概述2——算法复杂度估计
空间复杂度不可能超过时间复杂度S(n)=O(T(n))
数学归纳法

Master 定理Theorem

概述3——堆、堆排序
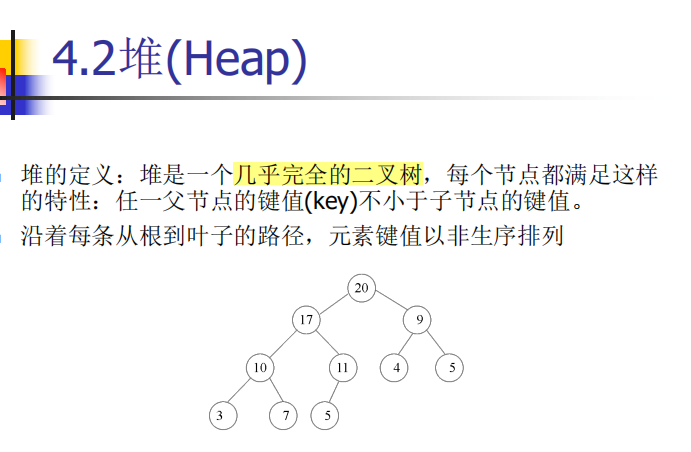
(比较)堆操作 ——堆排序:makeH()+n*delete()=> O(nlogn)
- 辅助运算Sift-up 。主要思想:就是不断的和父节点比,直到为根节点或比父节点小时停止
- 如果比父节点大,就互相替换,继续往上比。 O(logn)
- 辅助运算Sift-down。主要思想:就是不断的和子节点比,直到为叶子节点或比子节点都大时停止
- 如果比子节点小,就替换一个较大的子节点(左右相比),继续往下比。 O(logn)
- insert(H,x):插入元素x到堆H中。插入元素到堆尾,然后调用辅助运算Sift-up。 O(logn)
- delete(H,i)。删除当前元素,将堆尾元素替上来,然后辅助运算Sift-down。 O(logn)
- delete-max(H)。删除根元素。O(logn)
- make-heap(A): 从数组A创建堆。
- 方法1:从一个空堆开始,逐步插入A中的每个元素。O(nlogn)
- 方法2:遍历【n/2】->【1】,每个都要遍历Sift-down(A[i]),使以A[i]为根节点的子树调整成为堆。 O(nlogn) 比方法1略微划算一些

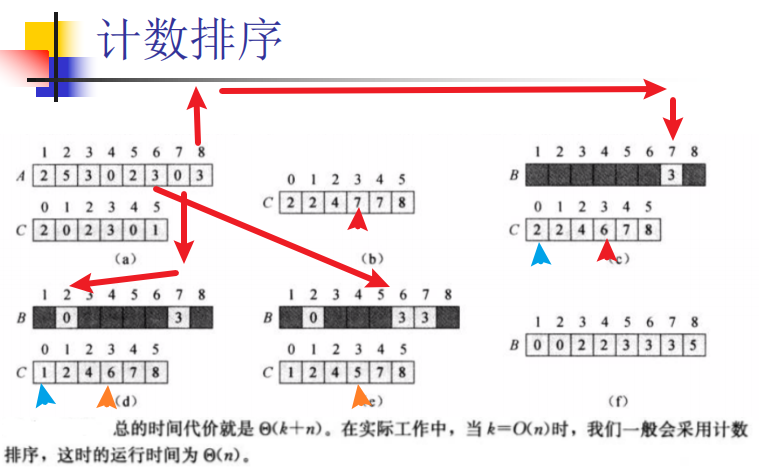
(非比较)计数排序 ——O(n+k),k=θ(n)的时候就是O(n)

(非比较)基数排序 ——Θ(kn)=Θ(n)

二、分治
合并排序算法 ——O(nlogn),加上θ(n)的空间复杂度
1 | Algorithm: MERGESORT(A[low…high]) |

分治的思想
- 划分:把规模较大的问题(n)分解为若干(通常为2)个规模较小的子问题(<n), 这些子问题相互独立且与原问题同类; (该子问题的规模减小到一定的程度就可以容易地解决)
- 治理:依次求出这些子问题的解
- 组合:把这些子问题的解组合起来得到原问题的解。
由于子问题与原问题是同类的,故分治法可以很自然地应用递归。

设计模式
1 | divide_and_conquer(P) |
快速排序——Θ(nlogn)
具体是
- 选定一个中心元素之后,就要将小于他的排在其后,大于他的排在其前
- 对分开的两个数组继续如上操作,不断分治(划分、治理)。组合
1 | Algorithm: QUICKSORT(A[low…high]) |
矩阵乘法
设A,B是两个n×n的矩阵,求C=AB.
方法1: 直接相乘法 O(n^3)
方法2: 分块矩阵法(直接应用分治策略) O(n^3)
方法3: Strassen算法(改进的分治策略) O(n^log^2^7^)=O(n^2.81)
其他问题
排列问题
- 已知集合R={r1, r2,…, rn},请设计一个算法生成集合R 中n 个元素的全排列
- 很简单,分治递归就好了
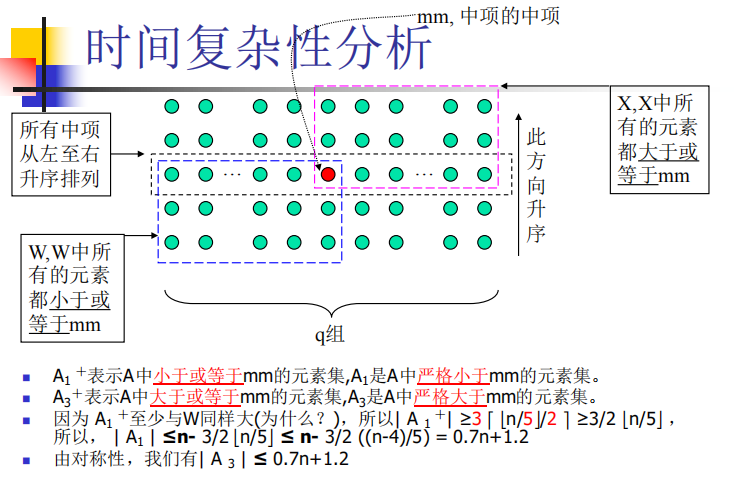
寻找中项和第k小元素 Tn=Θ(n)
寻找中项是寻找第k小元素的一个特列。如果能解决寻找第k小元素的问题,那么当k= ⎡ n/2 ⎤时,解决的就是寻找中项问题。
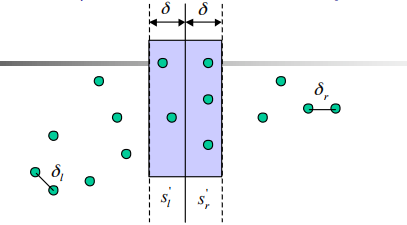
最接近点对问题
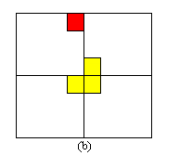
棋盘覆盖问题
在一个2k×2k 个方格组成的棋盘中,恰有一个方格与其他方格不同,称该方格为一特殊方格**(红色表示)**,且称该棋盘为一特殊棋盘。在棋盘覆盖问题中,要用图示的4种不同形态的L型骨牌覆盖给定的特殊棋盘上除特殊方格以外的所有方格,且任何2个L型骨牌不得重叠覆盖。


二、动态规划
借助于变量存储中间计算结果,消除重复计算。

基本思想

动态规划基本步骤
找出最优解的性质,并刻划其结构特征。
递归地定义最优值。
以自底向上的方式计算出最优值。
根据计算最优值时得到的信息,构造最优解。
矩阵链相乘 ——Θ(n^3^)
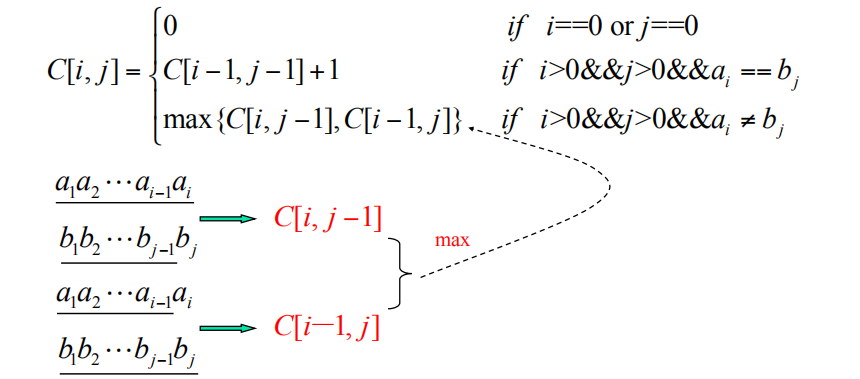
 可以递归地定义C[i,j]为:
可以递归地定义C[i,j]为:
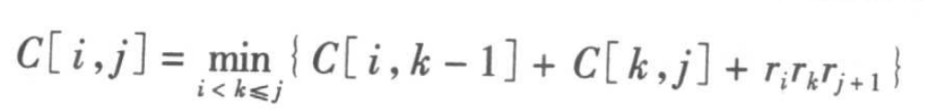

0-1背包问题 ✍
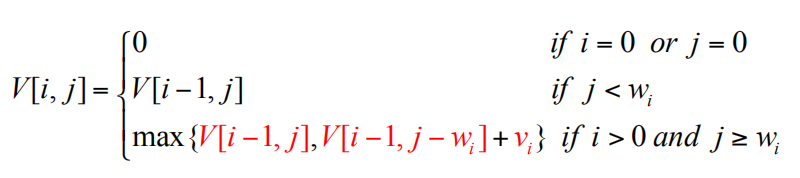
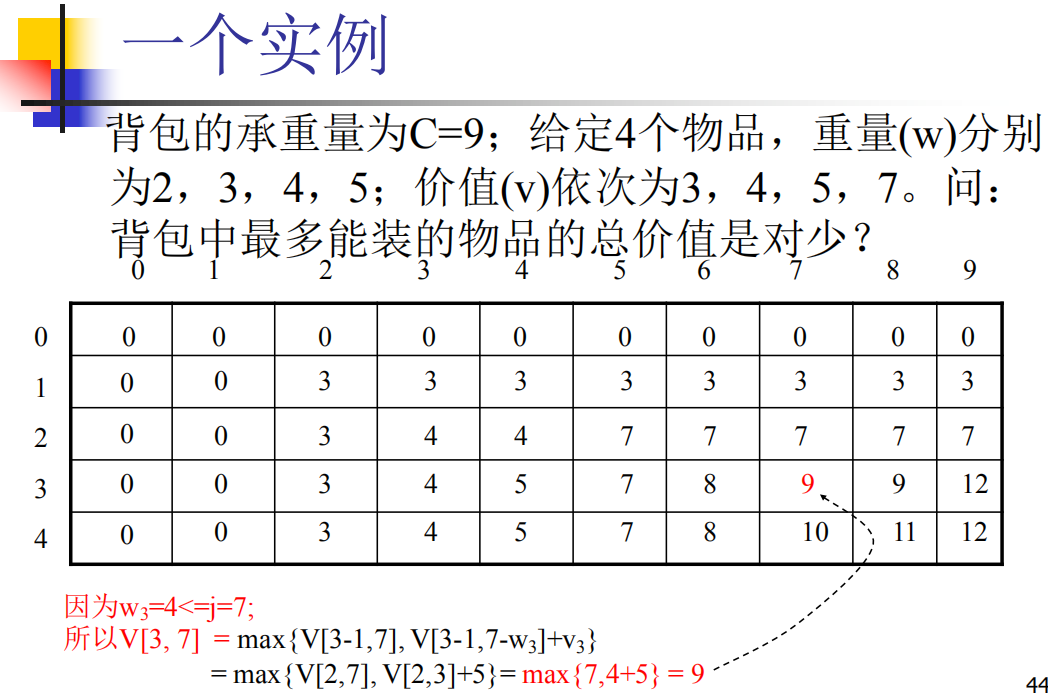

可是一维数组又会导致,前面更新的值,影响后面的值

最长公共子序列
给定两个定义在字符集∑上的字符串A和 B,长度分别为n和m,现在要求它们的最长公共子序列的长度值(最优值),以及对应的子序列(最优解) 。
其他问题
钢条切割问题:
最大子数组问题sum[i+1] = max(sum[i]+a[i+1], a[i+1])
爬楼梯(第二个楼梯就有两种走法。):dp[i] = dp[i-1]+dp[i-2]
最长连续有效括号长度:

三、贪心

活动安排问题

小数背包问题
计算每种物品的单位重量-价值作为贪心选择的依据指标,选择单位重量-价值最高的物品,将尽可能多的该物品装入背包,依此策略一直地进行下去,直到背包装满为止。
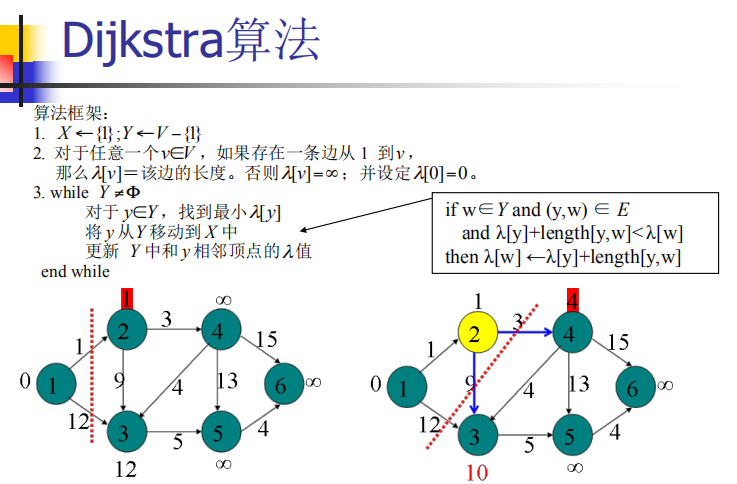
Dijkstra单源最短路径问题 ✍
给定带权有向图G =(V,E),其中每条边的权是非负实数。另外,还给定V中的一个顶点,称为源。现在要计算从源到所有其他各顶点的最短长度。这里路的长度是指路上各边权之和。这个问题通常称为单源最短路径问题。

单源最短路径(存在?):Bellman-Ford
- 推理:如果在|V|-1 次循环后,d[v]不能收敛,则存在权重为负的环路

最小生成树

Prim算法 ——避圈法 Θ(n^2^) ✍🆗

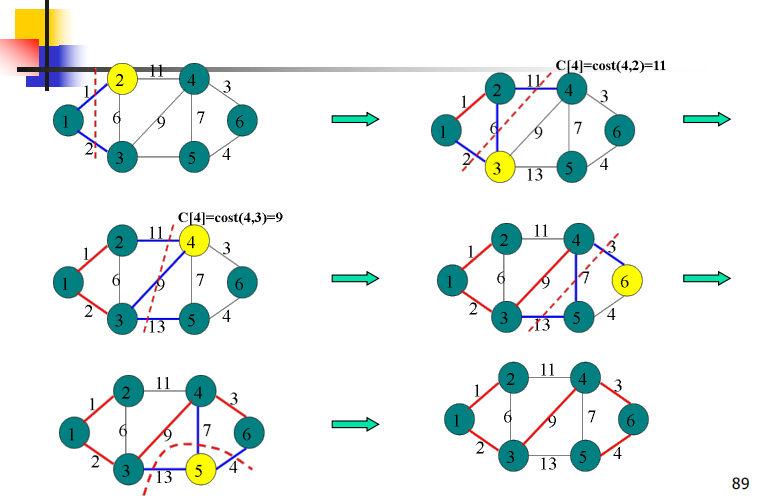
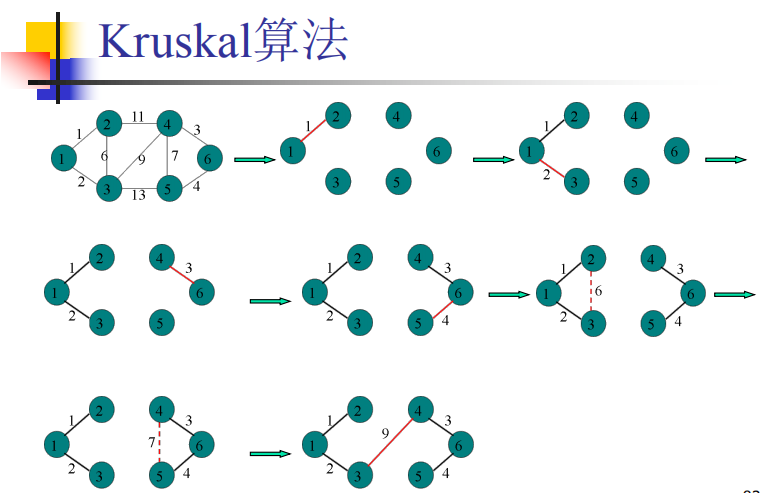
Kruskal算法 ——避圈法 O(mlogm+n) ✍🆗

破圈法 (” 圈”指的是回路)
求最小生成树有两种方法,一种是破圈法,另一种是避圈法(Kruskal,Prim也是求MST的算法)。
破圈法是“见圈破圈”,即如果看到图中有一个圈,就将这个圈的边去掉一条,直至图中再无一圈为止。
步骤如下:
- 在图中找一个回路
- 去掉该回路中权值最大的边,但要保持图仍为连通。
- 反复此过程,直至图中再无回路(但仍保持连通),得到最小生成树。
最后结果根据操作选取不同可能不唯一,但图的权值和(生成树的代价)相同,均为最小值。
避圈法则采取先将图中的点都取出来,然后,逐渐向上面添边,并保证后添入的边不与以前添上的边构成圈就可以了,这个过程直到将边集中能加入的边(加入后不够成圈)都加完为止。参见词条“Prim算法”和“Kruskal算法”。
其他问题
- 找硬币,最少找硬币数
- 霍夫曼编码:(编码)将每个码字连接起来。最低频的两个字符在最优编码树中,一定是深度最深的两个叶子
- 孩子分糖,最多满足孩子数,从最容易满足的孩子找最小的糖
四、图的遍历
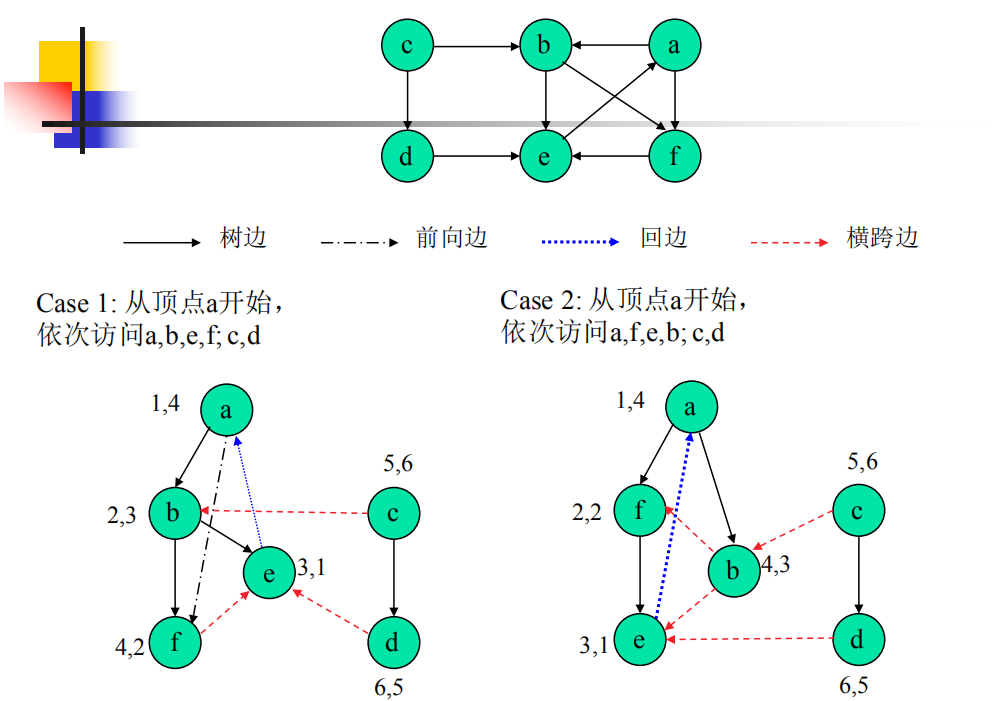
深度优先搜索树 ⭐

predfn(先序号):在图的深度优先搜索生成树(森林)中顶点的先序号,是指按照先序方式访问该生成树,该顶点的序号。
postdfn(后序号):在图的深度优先搜索生成树(森林)中顶点的后序号,是指按照后序方式访问该生成树,该顶点的序号。
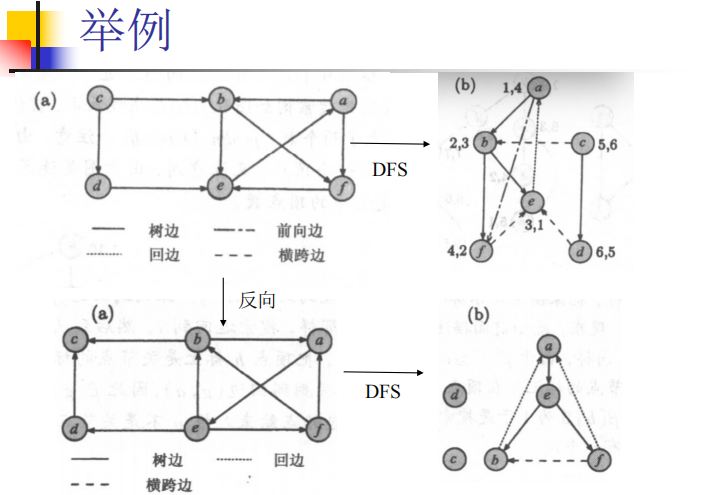
无向图只有两条边——树边、回边 (由于前向边、横跨边的定义)
*有向图情形 ——四种边 * Θ(n^2^ ) 使用邻接矩阵
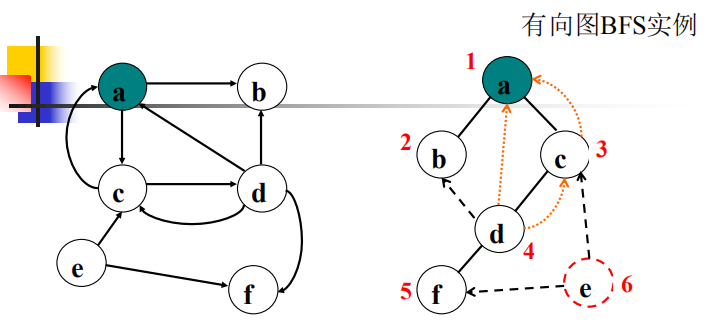
广度优先中:
在无向图中,边分为:树边或者是横跨边。(横跨边没有父子关系)
在有向图中,边分为:树边,回边及横跨边。不存在前向边。
树边(Tree edges)- 深度优先搜索生成树中的边:探测边(v,w)时,w是 “unvisited”状态,则边(v,w)是树边。
回边(Back edges)-在迄今为止所构建的深度优先搜索生成树中,w是v的祖先,并且在探测(v,w)时,w已经被标记为”visited”,则(v,w)为回边。
前向边(Forward edges)-在迄今为止所构建的深度优先搜索生成树中,w是v的后裔,并且在探测(v,w)时,w已经被标记为”visited”,则(v,w)为前向边。
横跨边(Cross edges)-所有其他的边。
广度优先搜索树
在无向图中,边分为:树边或者是横跨边。
在有向图中,边分为:树边,回边及横跨边。不存在前向边。
图的无回路性判定 有向/无向图

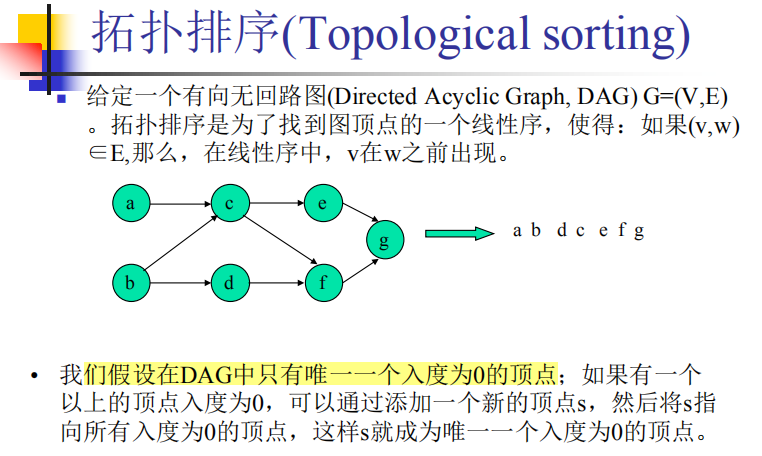
拓扑排序 ——有向图

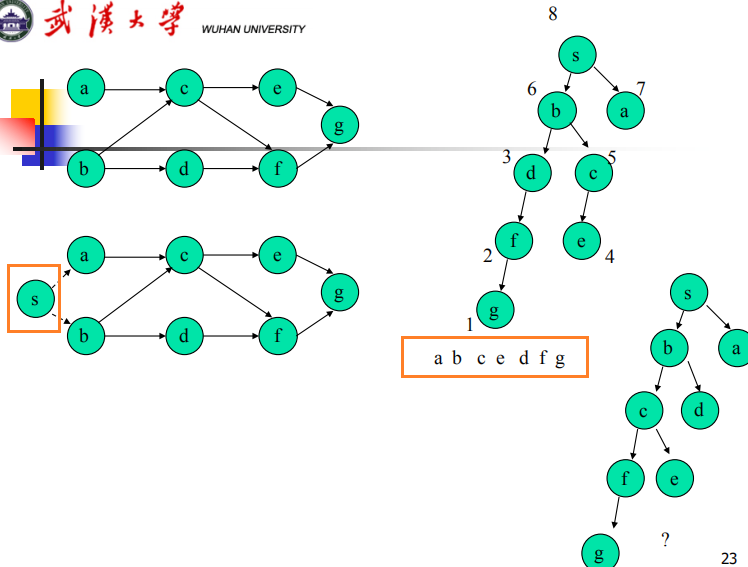
强连通分支 ——有向图 ✍
有向图G=(V,E),强连通集为顶点的极大集。在该集合中,每一对顶点都存在一条路径。

- 首先深度优先搜索,得到postdfn后序号
- 颠倒G中边的方向,构成一个新的图G’
- 图G’从最大的postdfn开始执行深搜,如果不能达到所有节点,换一个顶点继续
- 最后得到的森林中,每棵树对应一个强连通分支
五、回溯法
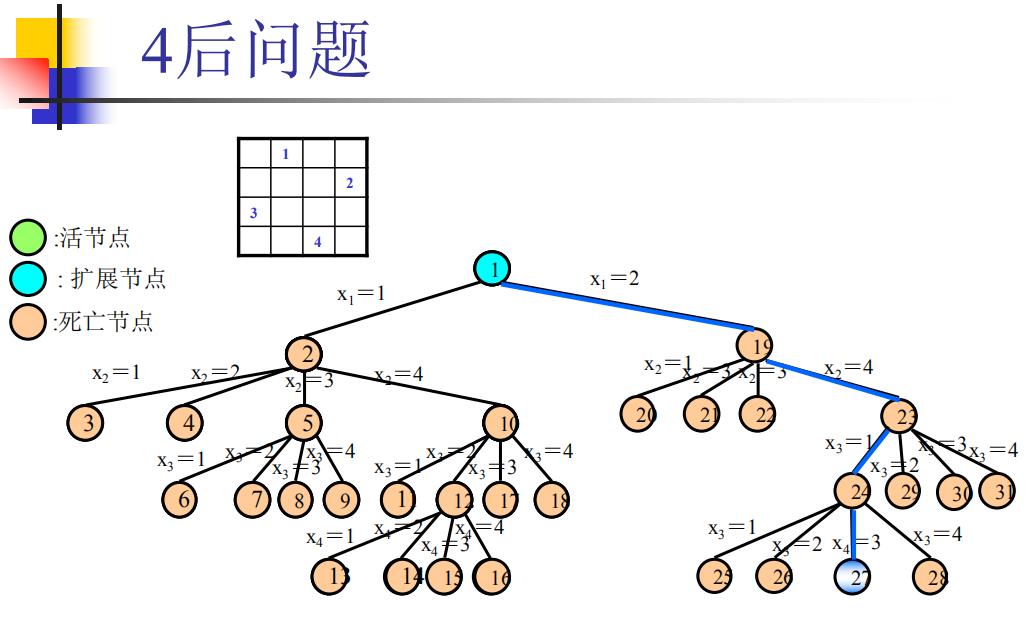
节点是由深度优先搜索方法生成的。不需要存储整棵搜索树,只需要存储根到当前活动节点的路径。
- 活节点:正常节点
- 扩展节点:当前节点,正在对此节点进行搜索
- 死节点:不可行节点,无需对其下面的节点进行搜索


框架

递归回溯

迭代回溯

皇后问题
所以,尽管在最坏情况下要用O(n^n^)时间来求解,然而大量实际经验表明,它在有效性上远远超过蛮力方法O(n!)。例如在4 皇后问题中,只搜索了341个节点中的27个就找到了解。


分支界限法 与 回溯法的区别(旅行商TSP)
分支限界法与回溯法的搜索方式不同
回溯法:深度优先
分支限界法:广度优先或最小耗费(最大收益)优先
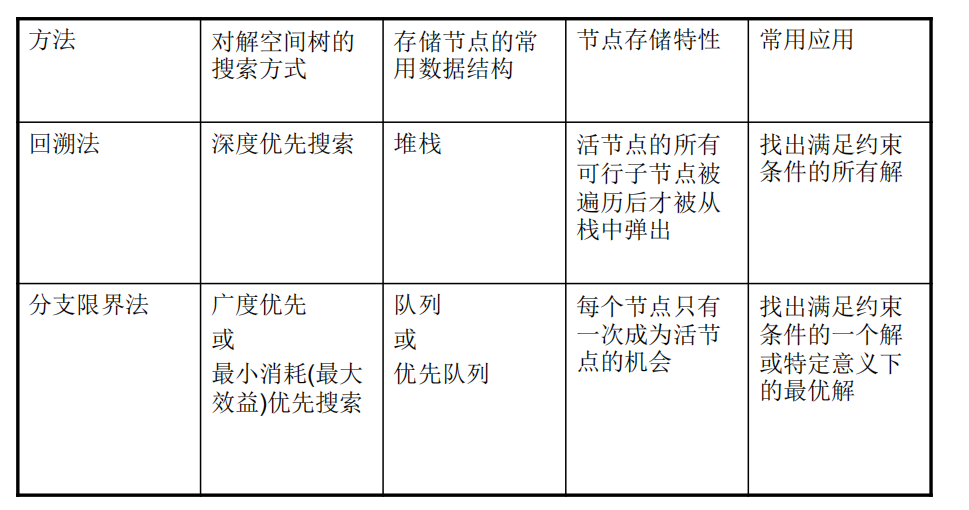
两种分支限界法:
队列式(FIFO)分支限界法(宽度优先):按照队列先进先出(FIFO)原则选取下一个节点为扩展节点。
优先队列式分支限界法(最小耗费或是最大收益优先):按照优先队列中规定的优先级选取优先级最高的节点成为当前扩展节点。
- 最大优先队列:使用最大堆,体现最大收益优先
- 最小优先队列:使用最小堆,体现最小耗费优先
旅行商
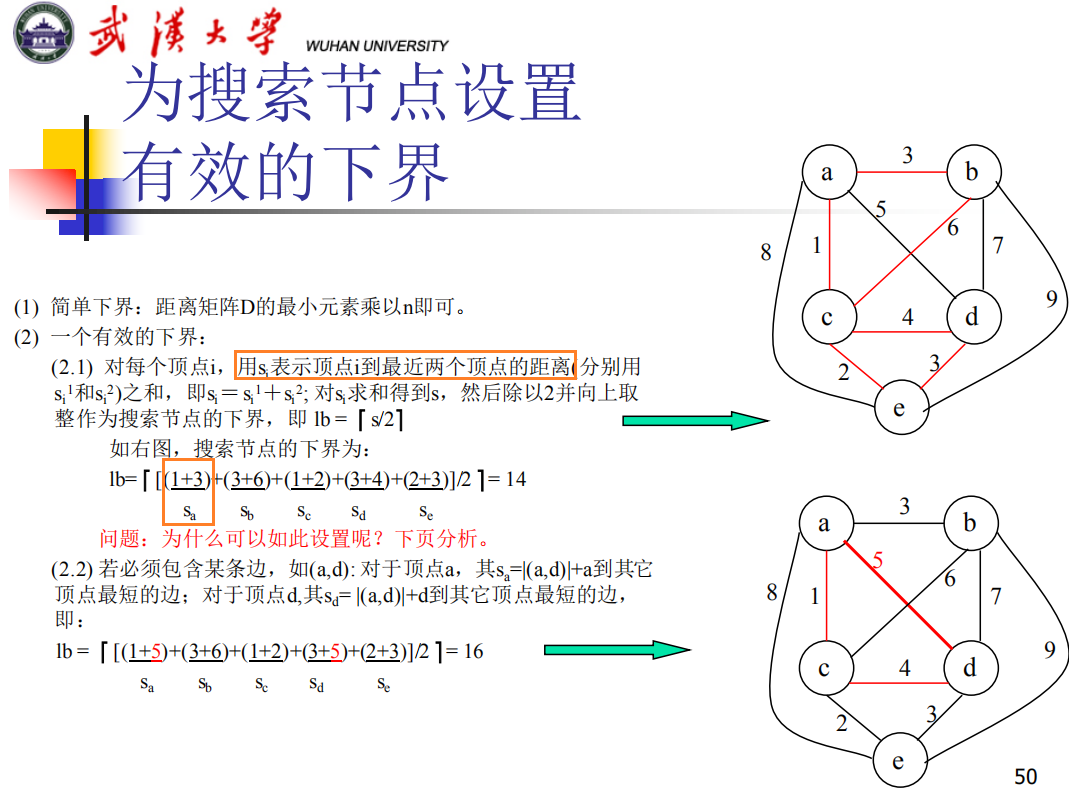
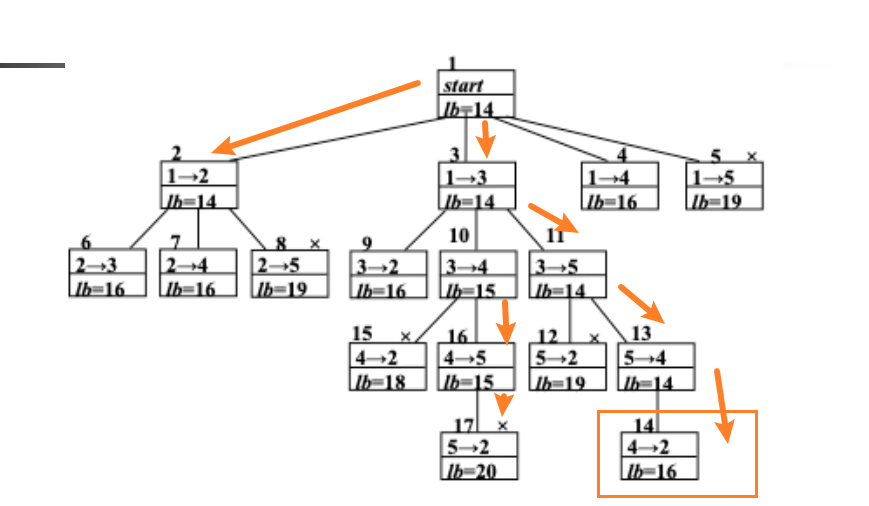
第六章、NP问题
如果对一个问题∏存在一个算法,时间复杂性为O(n^k^),其中n是问题规模,k是一个非负整数,则称问题∏存在多项式时间算法。这类算法在可以接受的时间内实现问题求解
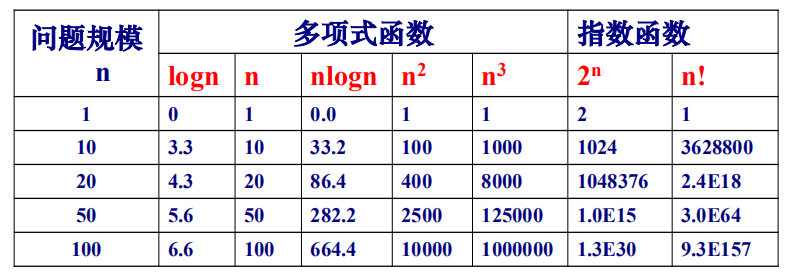
1. P、NP、NPC、co-NP
P属于NP,人们猜测P ≠ NP,但是否成立,至今未得到证明。
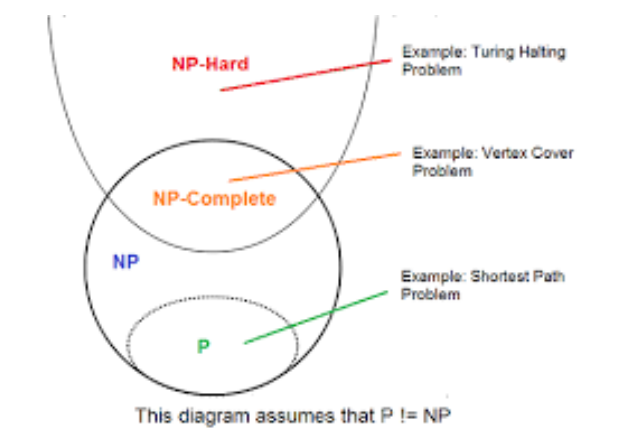
1 P类问题

2 NP类问题
非确定性算法:就是说,能以猜测和验证的方式工作,而且两个步骤都能在多项式时间内完成。

np问题:即每个实例都可以用非确定性算法得出一个yes/no的答案。

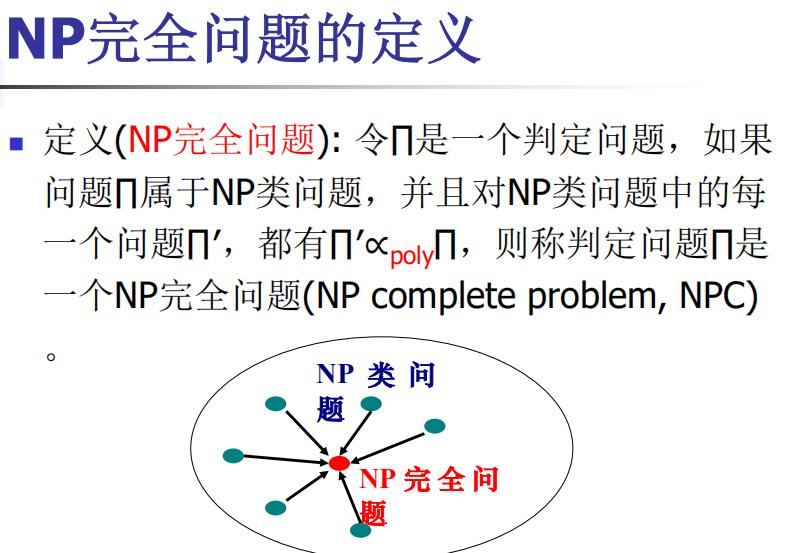
3 NPC问题
- 证明问题A是NP问题
- 证明一个已证的NPC问题可多项式输入转化为问题A,而其俩的输出可以相互转化。s
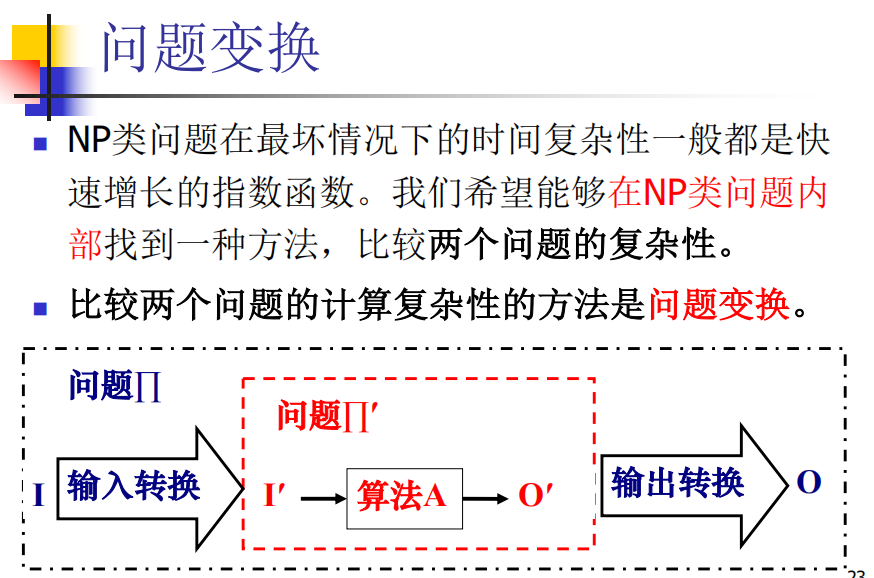
4 NP-Hard
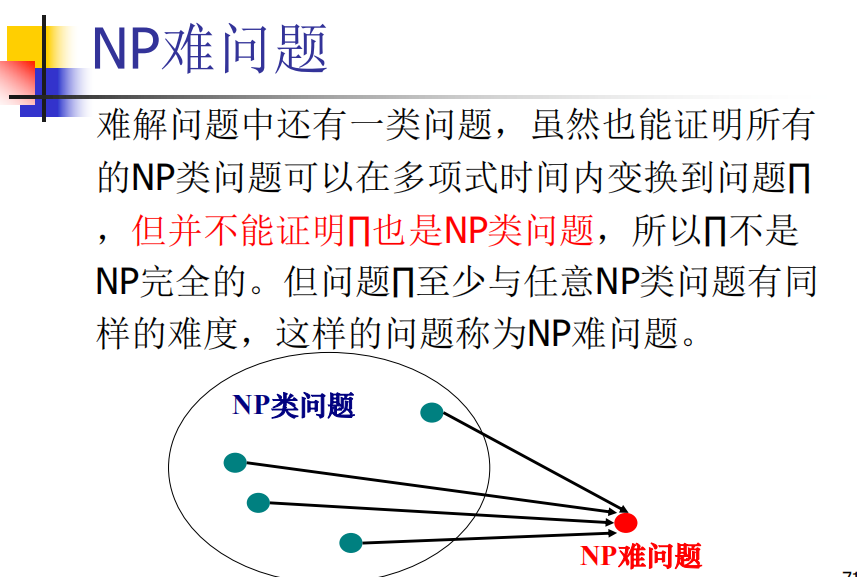
NP-Hard不是NP问题,但是和NPC一样难
5 co-NP问题
就是说,NP的猜测和验证只需要进行到某个x正确就结束了。co-NP的猜测和验证必须要全遍历全部x吗?
我是纠结在了,co-NP也是猜测和验证上的hh,现在看来确实不一样

2. 最大团 (SAT∝poly团) ⭐

3. 三元可满足性问题3SAT (SAT∝poly3SAT)

4. 顶点覆盖问题 (3SAT∝polyVC) 重点看📕



总结
第一章



第二章 动态规划



1 | def CHESS_COIN(c): |
第三章

第四章


第五章 回溯法

第六章